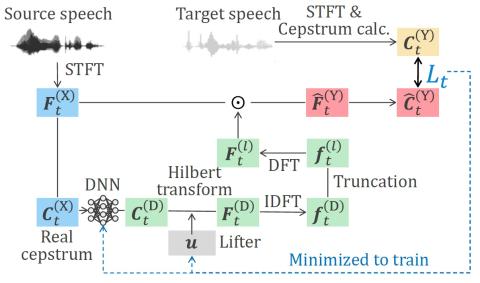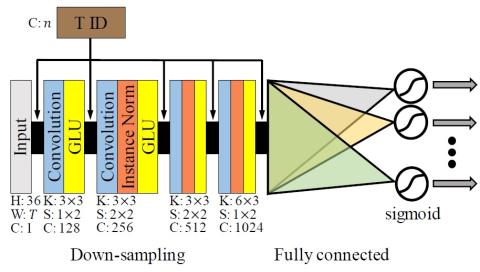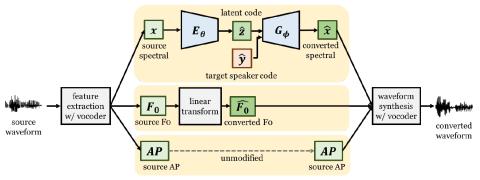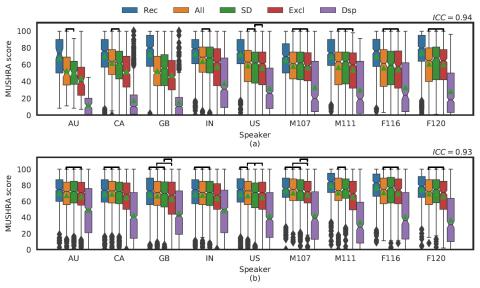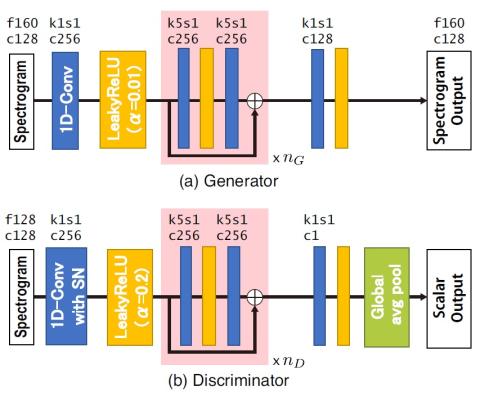
Scyclone: High-Quality and Parallel-Data-Free Voice Conversion Using Spectrogram and Cycle-Consistent Adversarial Networks
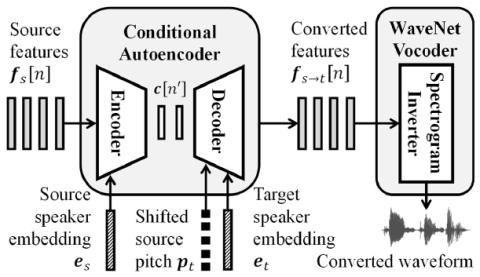
This paper proposes Scyclone, a high-quality voice conversion (VC) technique without parallel data training. Scyclone improves speech naturalness and speaker similarity of the converted speech by introducing CycleGAN-based spectrogram conversion with a simplified WaveRNN-based vocoder. In Scyclone, a linear spectrogram is used as the conversion features instead of vocoder parameters, which avoids quality degradation due to extraction errors in fundamental frequency and voiced/unvoiced parameters. The spectrogram of source and target speakers are modeled by modified CycleGAN networks, and the w...