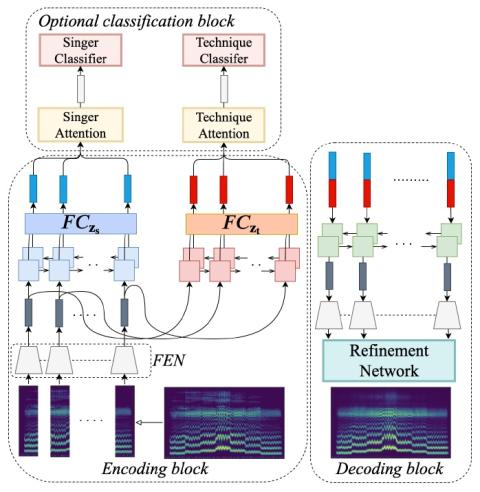
We propose a flexible framework that deals with both singer conversion and singers vocal technique conversion. The proposed model is trained on non-parallel corpora, accommodates many-to-many conversion, and leverages recent advances of variational autoencoders. It employs separate encoders to learn disentangled latent representations of singer identity and vocal technique separately, with a joint decoder for reconstruction. Conversion is carried out by simple vector arithmetic in the learned latent spaces. Both a quantitative analysis as well as a visualization of the converted spectrograms show that our model is able to disentangle singer identity and vocal technique and successfully perform conversion of these attributes. To the best of our knowledge, this is the first work to jointly tackle conversion of singer identity and vocal technique based on a deep learning approach.
Conclusion and Future Work
We have proposed a flexible framework based on GMVAEs to tackle non-parallel, many-to-many SVC for singer identity and vocal technique. Audio samples are available from https://reurl.cc/oD5vjQ. Analyzing the temporal dynamics of the latent variables, as well as accommodating the dependency between singer identity and vocal technique variables will be the focus of our future work.