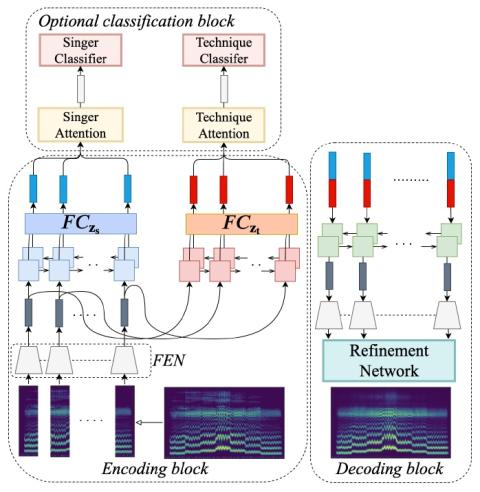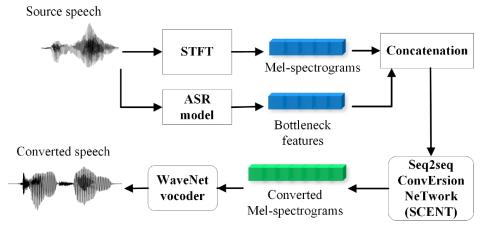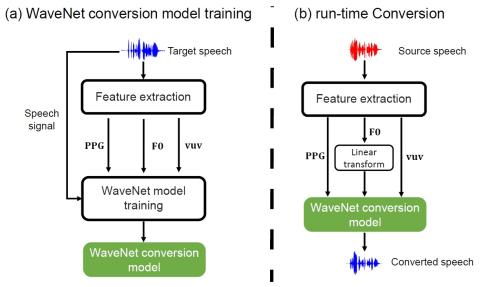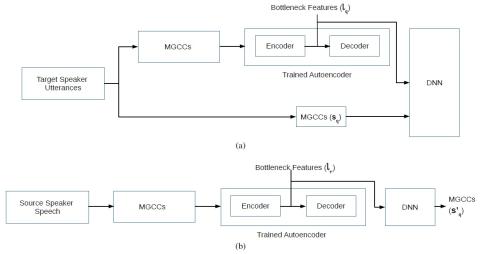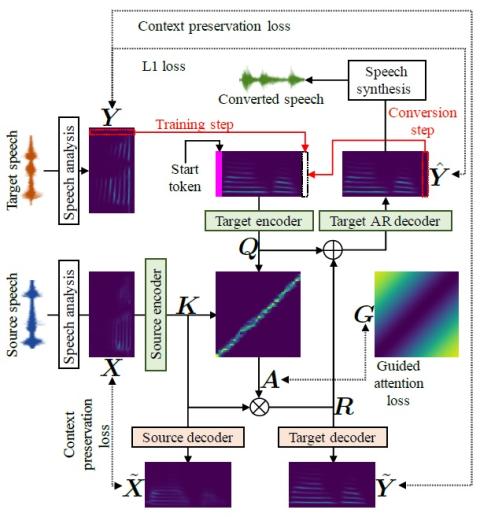
Transferring Source Style in Non-Parallel Voice Conversion
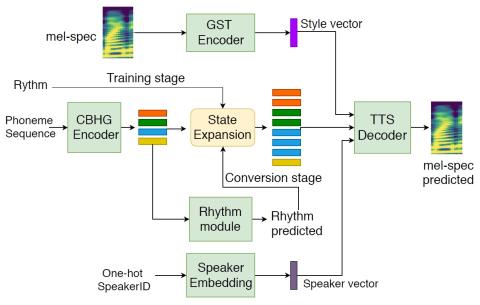
Voice conversion (VC) techniques aim to modify speaker identity of an utterance while preserving the underlying linguistic information. Most VC approaches ignore modeling of the speaking style (e.g. emotion and emphasis), which may contain the factors intentionally added by the speaker and should be retained during conversion. This study proposes a sequence-to-sequence based non-parallel VC approach, which has the capability of transferring the speaking style from the source speech to the converted speech by explicitly modeling. Objective evaluation and subjective listening tests show superior...