Cross-lingual voice conversion (CLVC) is a quite challenging task since the source and target speakers speak different languages. This paper proposes a CLVC framework based on bottleneck features and deep neural network (DNN). In the proposed method, the bottleneck features extracted from a deep auto-encoder (DAE) are used to represent speaker-independent features of speech signals from different languages. A DNN model is trained to learn the mapping between bottleneck features and the corresponding spectral features of the target speaker. The proposed method can capture speaker-specific characteristics of a target speaker, and hence requires no speech data from source speaker during training. The performance of the proposed method is evaluated using data from three Indian languages: Telugu, Tamil and Malayalam. The experimental results show that the proposed method outperforms the baseline Gaussian mixture model (GMM)-based CLVC approach.
Summary and Conclusion
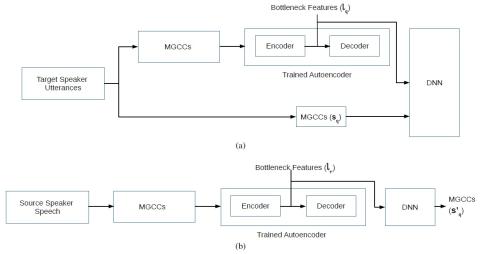
In this paper, we have presented a DAE-based cross-lingual voice conversion approach that can capture target speaker specific characteristics. The DAE is trained with data from multiple speakers to learn speaker-independent representations. Even though data from only one language is used to train DAE, the encoder performs robustly across acoustically closer languages. To build VC model for a given target speaker, first the MGCCs are passed through the encoder to derive bottleneck features. Then, a DNN is trained to predict MGCCs of target speaker from bottleneck features. The proposed approach does not require data from source speaker, and can map spectral features of any arbitrary source speaker onto a target speaker’s acoustic space. Hence, the proposed method can be considered as a “many-to-one mapping” method. The performance of the CLVC systems is evaluated using three acoustically similar Indian languages. The results of subjective evaluation confirm that both quality and target speaker similarity of converted speech from proposed CLVC system are much better than the baseline GMM-based CLVC system. In future, we plan to utilize the proposed CLVC technique to develop a polyglot SPSS system for Indian languages.