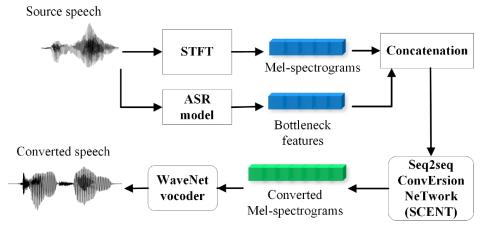
In this paper, a neural network named Sequence-to-sequence ConvErsion NeTwork (SCENT) is presented for acoustic modeling in voice conversion. At training stage, a SCENT model is estimated by aligning the feature sequences of source and target speakers implicitly using attention mechanism. At conversion stage, acoustic features and durations of source utterances are converted simultaneously using the unified acoustic model. Mel-scale spectrograms are adopted as acoustic features which contain both excitation and vocal tract descriptions of speech signals. The bottleneck features extracted from source speech using an automatic speech recognition (ASR) model are appended as auxiliary input. A WaveNet vocoder conditioned on Mel-spectrograms is built to reconstruct waveforms from the outputs of the SCENT model. It is worth noting that our proposed method can achieve appropriate duration conversion which is difficult in conventional methods. Experimental results show that our proposed method obtained better objective and subjective performance than the baseline methods using Gaussian mixture models (GMM) and deep neural networks (DNN) as acoustic models. This proposed method also outperformed our previous work which achieved the top rank in Voice Conversion Challenge 2018. Ablation tests further confirmed the effectiveness of several components in our proposed method.
Conclusion
This paper presents SCENT, a sequence-to-sequence neural network, for acoustic modeling in voice conversion. Mel-spectrograms are used as acoustic features. Bottleneck features extracted by an ASR model are taken as additional linguistic-related descriptions and are concatenated with the source acoustic features as network inputs. Taking advantage of the attention mechanism, the SCENT model does not rely on the preprocessing of DTW alignment and the duration conversion can be achieved simultaneously. Finally, the converted acoustic features are passed through a WaveNet vocoder to reconstruct speech waveforms. Objective and subjective experimental results demonstrated the superiority of our proposed method compared with baseline methods, especially in durational aspect. Ablation tests further proved the benefits of inputting Mel-spectrograms and the necessity of bottleneck features. The importance of the attention module and the positive effect of the location code were also proved in our ablation studies. To investigate the influence of training set size on the performance of our proposed method and to reduce conversion errors by improving attention calculation will be our work in the future.