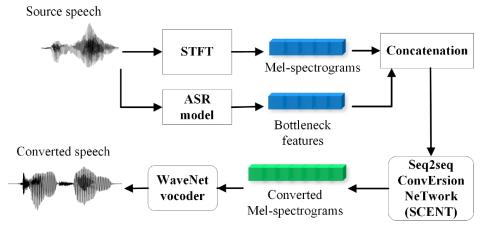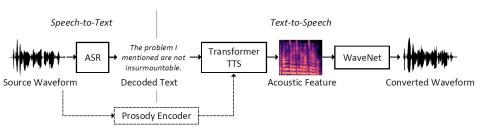
Voice Conversion by Cascading Automatic Speech Recognition and Text-to-Speech Synthesis with Prosody Transfer
With the development of automatic speech recognition (ASR) and text-to-speech synthesis (TTS) technique, it's intuitive to construct a voice conversion system by cascading an ASR and TTS system. In this paper, we present a ASR-TTS method for voice conversion, which used iFLYTEK ASR engine to transcribe the source speech into text and a Transformer TTS model with WaveNet vocoder to synthesize the converted speech from the decoded text. For the TTS model, we proposed to use a prosody code to describe the prosody information other than text and speaker information contained in speech. A prosody e...