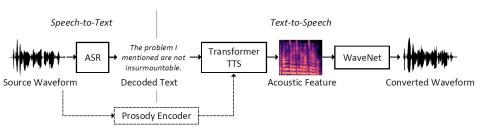
With the development of automatic speech recognition (ASR) and text-to-speech synthesis (TTS) technique, it's intuitive to construct a voice conversion system by cascading an ASR and TTS system. In this paper, we present a ASR-TTS method for voice conversion, which used iFLYTEK ASR engine to transcribe the source speech into text and a Transformer TTS model with WaveNet vocoder to synthesize the converted speech from the decoded text. For the TTS model, we proposed to use a prosody code to describe the prosody information other than text and speaker information contained in speech. A prosody encoder is used to extract the prosody code. During conversion, the source prosody is transferred to converted speech by conditioning the Transformer TTS model with its code. Experiments were conducted to demonstrate the effectiveness of our proposed method. Our system also obtained the best naturalness and similarity in the mono-lingual task of Voice Conversion Challenge 2020.
Conclusion
We present a voice conversion method by cascading a ASR and TTS module in this paper. iFLYTEK ASR engine is used for decoding text from the source utterance and a Transformer TTS model is trained for synthesizing the target speech. The Transformer TTS is pretrained on a multi-speaker dataset then fine-tuned on the target speaker in order to boosting its generalization capacity. A prosody transfer technique is further proposed, in which a prosody code is extracted by a prosody encoder from the source then used to condition the target TTS model. Our experimental results showed the effectiveness of proposed method for voice conversion. However, the ASR model is still imperfect. The speech recognition errors will lead to the change of the linguistic content of converted speech. Investigating on how to minimize those errors by using a mix of recognized text and the content-related features will be investigated in our future work.