Singing Voice Conversion with Disentangled Representations of Singer and Vocal Technique Using Variational Autoencoders
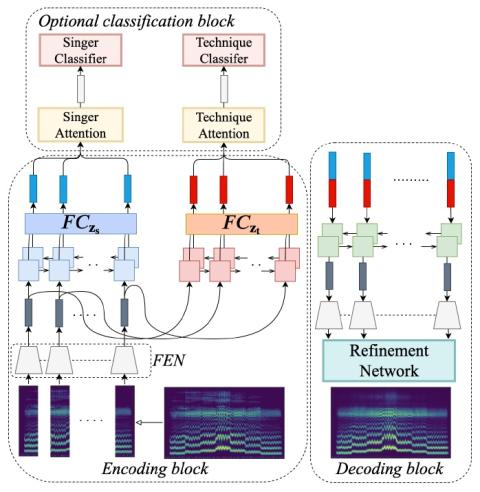
We propose a flexible framework that deals with both singer conversion and singers vocal technique conversion. The proposed model is trained on non-parallel corpora, accommodates many-to-many conversion, and leverages recent advances of variational autoencoders. It employs separate encoders to learn disentangled latent representations of singer identity and vocal technique separately, with a joint decoder for reconstruction. Conversion is carried out by simple vector arithmetic in the learned latent spaces. Both a quantitative analysis as well as a visualization of the converted spectrograms s...