We present an approach to synthesize whisper by applying a handcrafted signal processing recipe and Voice Conversion (VC) techniques to convert normally phonated speech to whispered speech. We investigate using Gaussian Mixture Models (GMM) and Deep Neural Networks (DNN) to model the mapping between acoustic features of normal speech and those of whispered speech. We evaluate naturalness and speaker similarity of the converted whisper on an internal corpus and on the publicly available wTIMIT corpus. We show that applying VC techniques is significantly better than using rule-based signal processing methods and it achieves results that are indistinguishable from copy-synthesis of natural whisper recordings. We investigate the ability of the DNN model to generalize on unseen speakers, when trained with data from multiple speakers. We show that excluding the target speaker from the training set has little or no impact on the perceived naturalness and speaker similarity of the converted whisper. The proposed DNN method is used in the newly released Whisper Mode of Amazon Alexa.
Conclusions
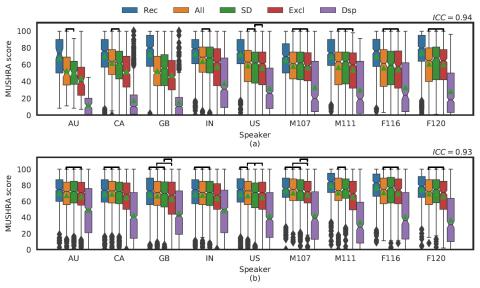
This paper was, to the best of our knowledge, the first study attempting to convert normal speech into whispered speech. We investigated using signal processing and two VC techniques (based on GMM and DNN models) to achieve this goal. We evaluated the three methods on both an internal corpus and on the wTIMIT public corpus.
We found out that the DSP recipe had a robust performance over all speakers from both corpora, however it is far from the theoretical limit imposed by the vocoder. All VC approaches however outperformed the DSP system in naturalness, intelligibility and speaker similarity evaluations. They reached the technical limit imposed by the vocoder and feature extraction chain. We showed that the DNN models can learn a speaker-independent mapping when trained on multiple speakers and that they are able to generalize and produce whispered speech for unseen speakers. We found that the DNN models can be robust to recording conditions if trained with varied enough data. The DNN model cannot generalize across genders and a gender balanced corpus is recommended for cross gender applications. The proposed DNN method was integrated into Amazon Alexa, and is used to generate the output for the newly released Whisper Mode.