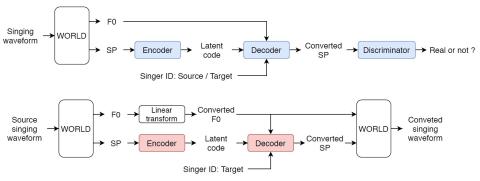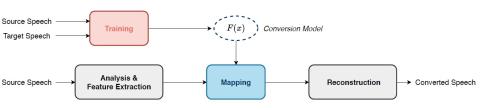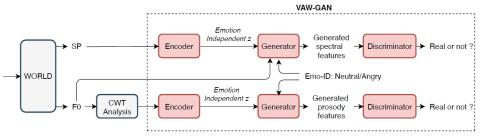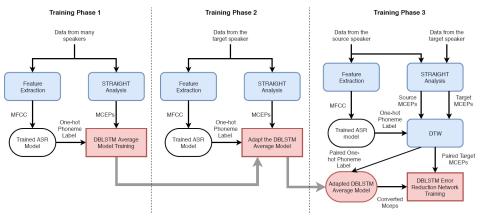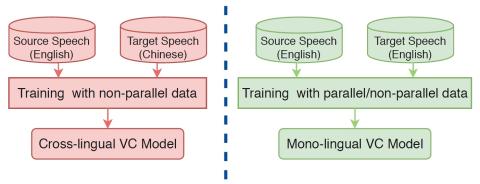
Spectrum and Prosody Conversion for Cross-lingual Voice Conversion with CycleGAN
Cross-lingual voice conversion aims to change source speaker's voice to sound like that of target speaker, when source and target speakers speak different languages. It relies on non-parallel training data from two different languages, hence, is more challenging than mono-lingual voice conversion. Previous studies on cross-lingual voice conversion mainly focus on spectral conversion with a linear transformation for F0 transfer. However, as an important prosodic factor, F0 is inherently hierarchical, thus it is insufficient to just use a linear method for conversion. We propose the use of conti...