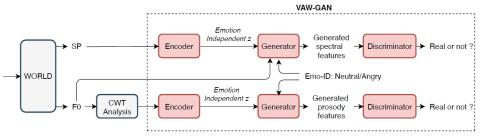
Emotional voice conversion aims to convert the emotion of the speech from one state to another while preserving the linguistic content and speaker identity. The prior studies on emotional voice conversion are mostly carried out under the assumption that emotion is speaker-dependent. We believe that emotions are expressed universally across speakers, therefore, the speaker-independent mapping between emotional states of speech is possible. In this paper, we propose to build a speaker-independent emotional voice conversion framework, that can convert anyone's emotion without the need for parallel data. We propose a VAW-GAN based encoder-decoder structure to learn the spectrum and prosody mapping. We perform prosody conversion by using continuous wavelet transform (CWT) to model the temporal dependencies. We also investigate the use of F0 as an additional input to the decoder to improve emotion conversion performance. Experiments show that the proposed speaker-independent framework achieves competitive results for both seen and unseen speakers.
Conclusions
In this paper, we propose a speaker-independent emotional voice conversion framework that converts anyone’s emotion without the need for parallel training data. We perform both spectrum and prosody conversion based on VAW-GAN.We provide CWT modelling of F0 to describe the prosody in different time resolutions. Moreover, we study the use of CWT-based F0 as an additional input to the decoder to improve the spectrum conversion performance. Experimental results validate the idea of speaker-independent emotion conversion by showing remarkable performance for both seen and unseen speakers.
This study highlights the need for a large emotional voice conversion corpus that will be our future focus.