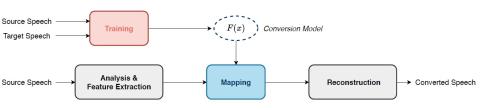
Speaker identity is one of the important characteristics of human speech. In voice conversion, we change the speaker identity from one to another, while keeping the linguistic content unchanged. Voice conversion involves multiple speech processing techniques, such as speech analysis, spectral conversion, prosody conversion, speaker characterization, and vocoding. With the recent advances in theory and practice, we are now able to produce human-like voice quality with high speaker similarity. In this paper, we provide a comprehensive overview of the state-of-the-art of voice conversion techniques and their performance evaluation methods from the statistical approaches to deep learning, and discuss their promise and limitations. We will also report the recent Voice Conversion Challenges (VCC), the performance of the current state of technology, and provide a summary of the available resources for voice conversion research.
Conclusion
This article provides a comprehensive overview of the voice conversion technology, covering the fundamentals and practice till July 2020. We reveal the underlying technologies and their relationship from the statistical approaches to deep learning, and discuss their promise and limitations. We also study the evaluation techniques for voice conversion. Moreover, we report the series of voice conversion challenges and resources that are useful information for researchers and engineers to start voice conversion research.