So far, many of the deep learning approaches for voice conversion produce good quality speech by using a large amount of training data. This paper presents a Deep Bidirectional Long Short-Term Memory (DBLSTM) based voice conversion framework that can work with a limited amount of training data. We propose to implement a DBLSTM based average model that is trained with data from many speakers. Then, we propose to perform adaptation with a limited amount of target data. Last but not least, we propose an error reduction network that can improve the voice conversion quality even further. The proposed framework is motivated by three observations. Firstly, DBLSTM can achieve a remarkable voice conversion by considering the long-term dependencies of the speech utterance. Secondly, DBLSTM based average model can be easily adapted with a small amount of data, to achieve a speech that sounds closer to the target. Thirdly, an error reduction network can be trained with a small amount of training data, and can improve the conversion quality effectively. The experiments show that the proposed voice conversion framework is flexible to work with limited training data and outperforms the traditional frameworks in both objective and subjective evaluations.
Conclusions
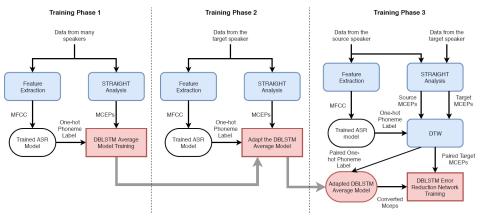
This paper presents an error reduction network for adapted DBLSTM-based voice conversion approach, which can achieve a good performance with limited parallel data of the source speaker and the target speaker. Firstly, we propose to train an average model for the one-hot phoneme label to MCEPs mapping with data from many speakers exclude the source speaker and the target speaker. Then, we propose to adapt the average model with a limited amount of target data. Furthermore, we implement an error reduction network that can improve the voice conversion quality. Experiment results from both objective and subjective evolution show that our proposed approach can make a good use of limited data, and outperforms the baseline approach. In the future, we will investigate to use the WaveNet Vocoder, which is a convolutional neural network that can generate raw audio waveform sample by sample, to improve the quality and naturalness of the converted speech. Some samples for the listening test are available through this link: https://arkhamimp.github.io/ErrorReductionNetwork/