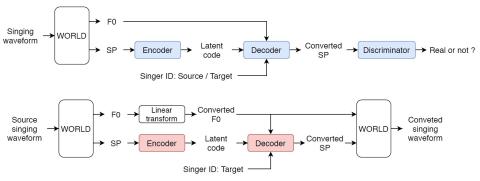
Singing voice conversion aims to convert singer's voice from source to target without changing singing content. Parallel training data is typically required for the training of singing voice conversion system, that is however not practical in real-life applications. Recent encoder-decoder structures, such as variational autoencoding Wasserstein generative adversarial network (VAW-GAN), provide an effective way to learn a mapping through non-parallel training data. In this paper, we propose a singing voice conversion framework that is based on VAW-GAN. We train an encoder to disentangle singer identity and singing prosody (F0 contour) from phonetic content. By conditioning on singer identity and F0, the decoder generates output spectral features with unseen target singer identity, and improves the F0 rendering. Experimental results show that the proposed framework achieves better performance than the baseline frameworks.
Conclusion
In this paper, we propose a parallel-data-free singing voice conversion framework with VAW-GAN. We first propose to conduct singer-independent training with a encoding-decoding process. We also propose to condition F0 on the decoder to improve the singing conversion performance. We eliminate the need for parallel training data or other time-alignment procedures, and achieve high performance of the converted singing voices. Experimental results show the efficiency of our proposed SVC framework both on intra-gender and inter-gender singing voice conversion.