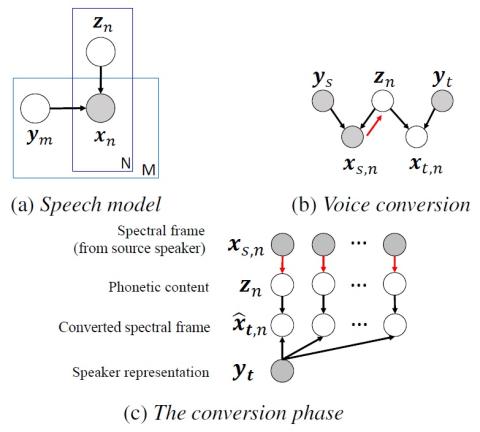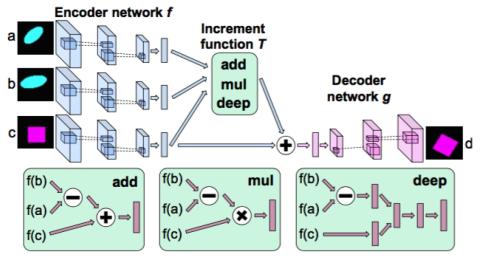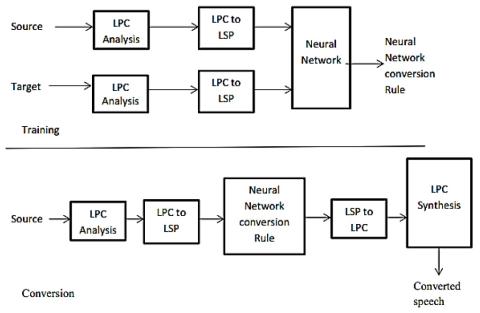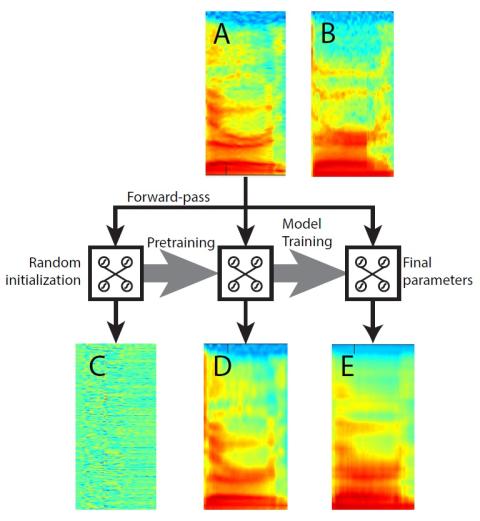
Parallel-Data-Free Voice Conversion Using Cycle-Consistent Adversarial Networks
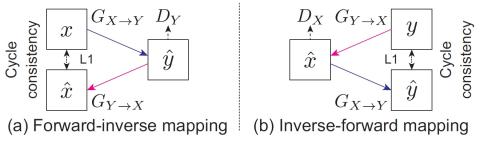
We propose a parallel-data-free voice-conversion (VC) method that can learn a mapping from source to target speech without relying on parallel data. The proposed method is general purpose, high quality, and parallel-data free and works without any extra data, modules, or alignment procedure. It also avoids over-smoothing, which occurs in many conventional statistical model-based VC methods. Our method, called CycleGAN-VC, uses a cycle-consistent adversarial network (CycleGAN) with gated convolutional neural networks (CNNs) and an identity-mapping loss. A CycleGAN learns forward and inverse map...