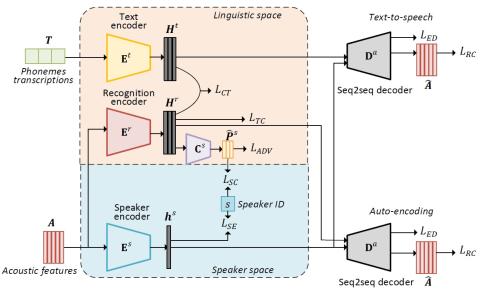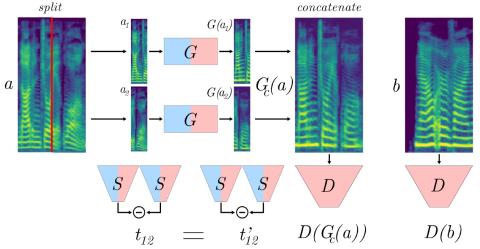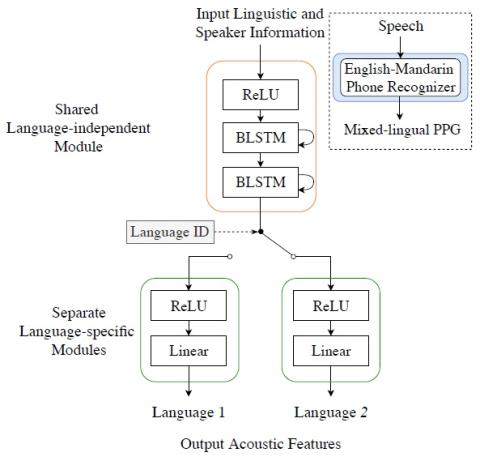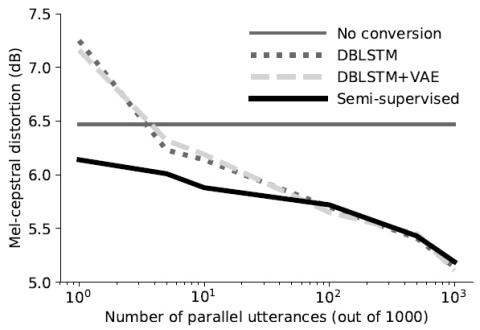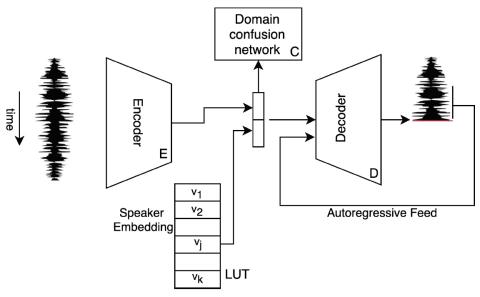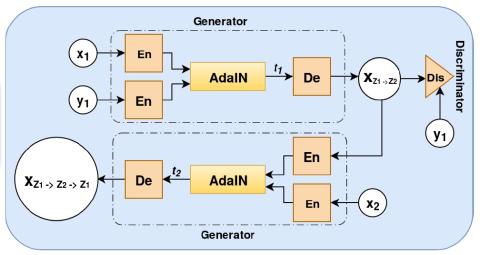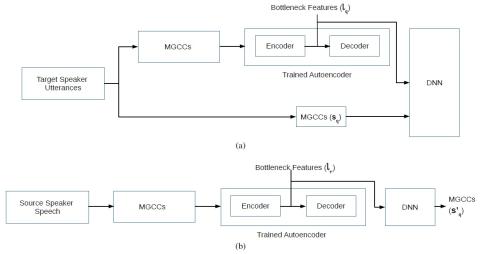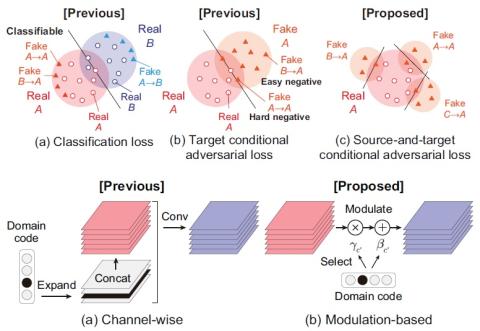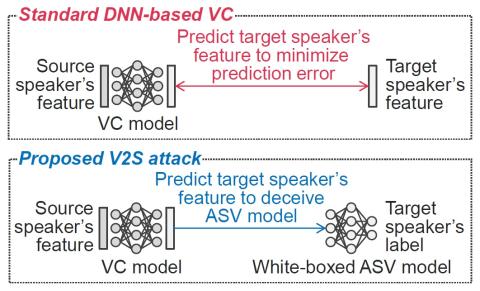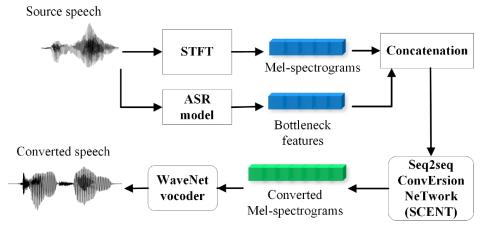
Sequence-to-Sequence Acoustic Modeling for Voice Conversion
In this paper, a neural network named Sequence-to-sequence ConvErsion NeTwork (SCENT) is presented for acoustic modeling in voice conversion. At training stage, a SCENT model is estimated by aligning the feature sequences of source and target speakers implicitly using attention mechanism. At conversion stage, acoustic features and durations of source utterances are converted simultaneously using the unified acoustic model. Mel-scale spectrograms are adopted as acoustic features which contain both excitation and vocal tract descriptions of speech signals. The bottleneck features extracted from ...