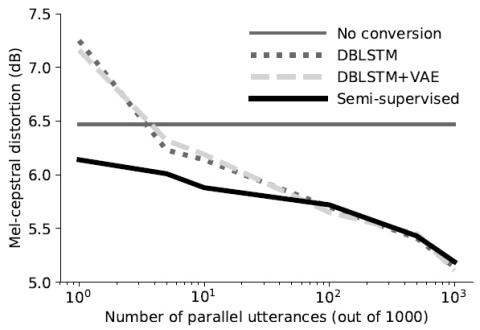
In this work we introduce a semi-supervised approach to the voice conversion problem, in which speech from a source speaker is converted into speech of a target speaker. The proposed method makes use of both parallel and non-parallel utterances from the source and target simultaneously during training. This approach can be used to extend existing parallel data voice conversion systems such that they can be trained with semi-supervision. We show that incorporating semi-supervision improves the voice conversion performance compared to fully supervised training when the number of parallel utterances is limited as in many practical applications. Additionally, we find that increasing the number non-parallel utterances used in training continues to improve performance when the amount of parallel training data is held constant.
Conclusion
We have proposed a new semi-supervised method for achieving voice conversion using both parallel and non-parallel data. This method incorporates both types of data simultaneously during training by optimizing a variational objective defined for paired and unpaired utterances. When only a small number of parallel utterances are available, we show that incorporating this method into an existing neural network model improves the accuracy and perceptual quality of the converted speech compared to supervised training. We also find that increasing the amount of non-parallel data continues to improve voice conversion. This opens up the possibility of training VC systems with more flexible datasets consisting of mixed parallel and non-parallel data.