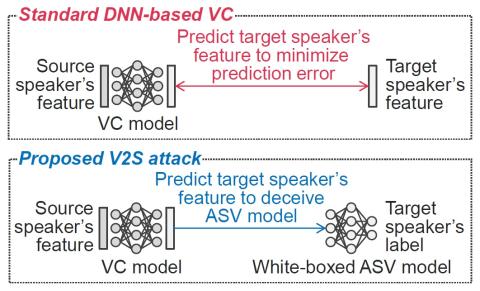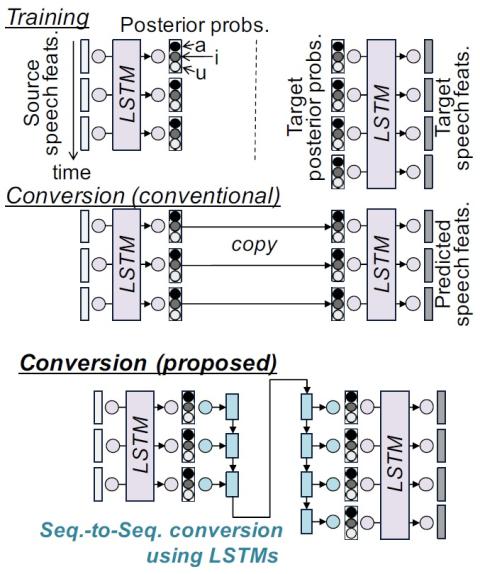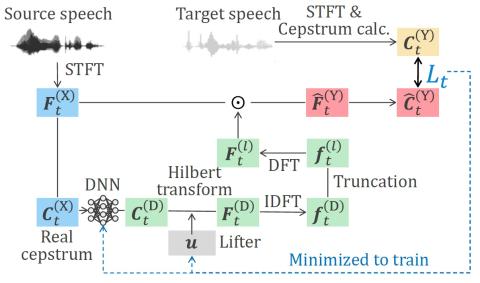
Lifter Training and Sub-band Modeling for Computationally Efficient and High-Quality Voice Conversion Using Spectral Differentials
In this paper, we propose computationally efficient and high-quality methods for statistical voice conversion (VC) with direct waveform modification based on spectral differentials. The conventional method with a minimum-phase filter achieves high-quality conversion but requires heavy computation in filtering. This is because the minimum phase using a fixed lifter of the Hilbert transform often results in a long-tap filter. One of our methods is a data-driven method for lifter training. Since this method takes filter truncation into account in training, it can shorten the tap length of the fil...