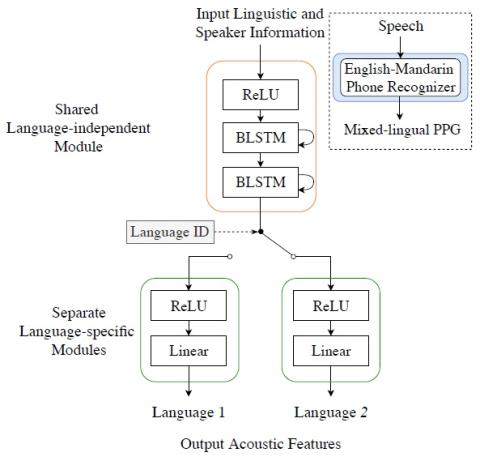
This paper presents a cross-lingual voice conversion framework that adopts a modularized neural network. The modularized neural network has a common input structure that is shared for both languages, and two separate output modules, one for each language. The idea is motivated by the fact that phonetic systems of languages are similar because humans share a common vocal production system, but acoustic renderings, such as prosody and phonotactic, vary a lot from language to language. The modularized neural network is trained to map Phonetic PosteriorGram (PPG) to acoustic features for multiple speakers. It is conditioned on a speaker i-vector to generate the desired target voice. We validated the idea between English and Mandarin languages in objective and subjective tests. In addition, mixed-lingual PPG derived from a unified English-Mandarin acoustic model is proposed to capture the linguistic information from both languages. It is found that our proposed modularized neural network significantly outperforms the baseline approaches in terms of speech quality and speaker individuality, and mixed-lingual PPG representation further improves the conversion performance.
Conclusion
In this paper, we proposed a cross-lingual voice conversion framework based on a modularized neural network using mix-language PPG. By utilizing the shared input module to be language independent while decomposing the output modules to be language specific, the network is robust for output acoustic feature modeling across different languages. Meanwhile, the mixed-lingual PPG extracted from a unified English-Mandarin acoustic model also provides an accurate linguistic representation for conversion quality enhancement. Experimental results successfully demonstrate our proposed approaches outperform the baseline approaches on both speech quality and speaker similarity.