Voice Conversion (VC) is a task of converting perceived speaker identity from a source speaker to a particular target speaker. Earlier approaches in the literature primarily find a mapping between the given source-target speaker-pairs. Developing mapping techniques for many-to-many VC using non-parallel data, including zero-shot learning remains less explored areas in VC. Most of the many-to-many VC architectures require training data from all the target speakers for whom we want to convert the voices. In this paper, we propose a novel style transfer architecture, which can also be extended to generate voices even for target speakers whose data were not used in the training (i.e., case of zero-shot learning). In particular, propose Adaptive Generative Adversarial Network (AdaGAN), new architectural training procedure help in learning normalized speaker-independent latent representation, which will be used to generate speech with different speaking styles in the context of VC. We compare our results with the state-of-the-art StarGAN-VC architecture. In particular, the AdaGAN achieves 31.73%, and 10.37% relative improvement compared to the StarGAN in MOS tests for speech quality and speaker similarity, respectively. The key strength of the proposed architectures is that it yields these results with less computational complexity. AdaGAN is 88.6% less complex than StarGAN-VC in terms of FLoating Operation Per Second (FLOPS), and 85.46% less complex in terms of trainable parameters.
Conclusions and Future Work
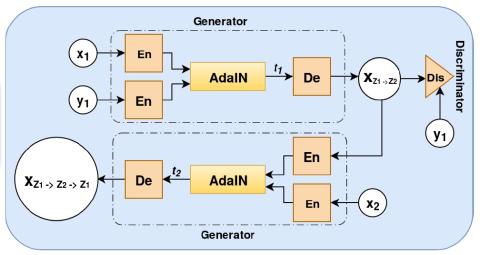
In this paper, we proposed novel AdaGAN primarily for non-parallel many-to-many VC task. Moreover, we analyzed our proposed architecture w.r.t. current GAN-based state-of-the-art StarGAN-VC method for the same task. We know that the main aim of VC is to convert the source speaker’s voice into the target speaker’s voice while preserving linguistic content. To achieve this, we have used the style transfer algorithm along with the adversarial training. AdaGAN transfers the style of the target speaker into the voice of a source speaker without using any feature-based mapping between the linguistic content of the source speaker’s speech. For this task, AdaGAN uses only one generator and one discriminator, which leads to less complexity. AdaGAN is almost 88.6% computationally less complex than the StarGAN-VC.We have performed subjective analysis on the VCTK corpus to show the efficiency of the proposed method. We can clearly see that AdaGAN gives superior results in the subjective evaluations compared to StarGAN-VC.
Motivated by the work of AutoVC, we also extended the concept of AdaGAN for the zero-shot conversion as an independent study and reported results. AdaGAN is the first GAN-based framework for zero-shot VC. In the future, we plan to explore high-quality vocoders, namely,WaveNet, for further improvement in voice quality. The perceptual difference observed between the estimated and the ground truth indicates the need for exploring better objective function that can perceptually optimize the network parameters of GAN-based architectures, which also forms our immediate future work.