The human auditory system is able to distinguish the vocal source of thousands of speakers, yet not much is known about what features the auditory system uses to do this. Fourier Transforms are capable of capturing the pitch and harmonic structure of the speaker but this alone proves insufficient at identifying speakers uniquely. The remaining structure, often referred to as timbre, is critical to identifying speakers but we understood little about it. In this paper we use recent advances in neural networks in order to manipulate the voice of one speaker into another by transforming not only the pitch of the speaker, but the timbre. We review generative models built with neural networks as well as architectures for creating neural networks that learn analogies. Our preliminary results converting voices from one speaker to another are encouraging.
Conclusion
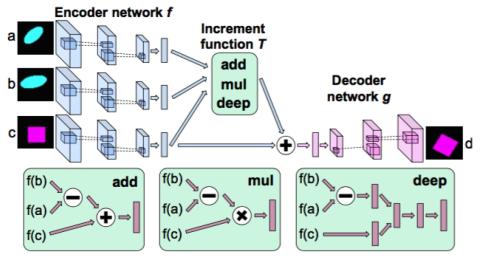
We began by developing algorithms in order to transfer the timbre of one speaker to another. Our algorithms were able to produce speech that occassionally sounded perceptually similar to the target speaker but work remains to be done. Training Generative Adversarial Networks has proven very difficult in practice and more time will need to be spent understanding how best optimize the Conditional Generative Adversarial Network model developed here.