Voice conversion methods have advanced rapidly over the last decade. Studies have shown that speaker characteristics are captured by spectral feature as well as various prosodic features. Most existing conversion methods focus on the spectral feature as it directly represents the timbre characteristics, while some conversion methods have focused only on the prosodic feature represented by the fundamental frequency. In this paper, a comprehensive framework using deep neural networks to convert both timbre and prosodic features is proposed. The timbre feature is represented by a high-resolution spectral feature. The prosodic features include F0, intensity and duration. It is well known that DNN is useful as a tool to model high-dimensional features. In this work, we show that DNN initialized by our proposed autoencoder pretraining yields good quality DNN conversion models. This pretraining is tailor-made for voice conversion and leverages on autoencoder to capture the generic spectral shape of source speech. Additionally, our framework uses segmental DNN models to capture the evolution of the prosodic features over time. To reconstruct the converted speech, the spectral feature produced by the DNN model is combined with the three prosodic features produced by the DNN segmental models. Our experimental results show that the application of both prosodic and high-resolution spectral features leads to quality converted speech as measured by objective evaluation and subjective listening tests.
Conclusions
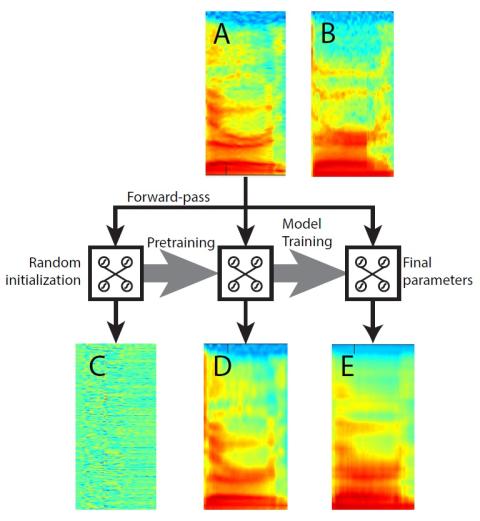
This paper showcases a comprehensive voice conversion framework, in which high-resolution spectra, F0, intensity and segment duration are all converted using DNNs. The objective and subjective evaluations shows the capability of the modeling of high-dimensional full spectra and prosodic segments. The proposed autoencoder pretraining for voice conversion is shown to effectively initialize the model parameters and leads to accurate spectral estimation. The resultant spectral conversion model with our proposed pretraining achieves comparable ratings in terms of similarity and quality as another state-of-the-art pretrained voice conversion system.
In conventional works of voice conversion, prosodic features are not commonly modeled. Knowing that human manipulates prosody in various levels, rather than in a local frame basis, we have introduced segment-level modeling and conversion for F0, intensity and duration, without increasing the amount of training data of typical voice conversion scenarios. Our experimental results have shown that the resultant converted speech is much similar to the target speaker. Throughout this work, a feasible conversion framework is built where multiple features are transformed acoustically and future investigations on ways of modeling and conversion of timbre and prosodic features remain thought-provoking. To better understand the performance of intensity and duration conversion, we plan to evaluate the perceptual effect of intensity and duration modification on voice conversion through more intensive psychoacoustic experiments.