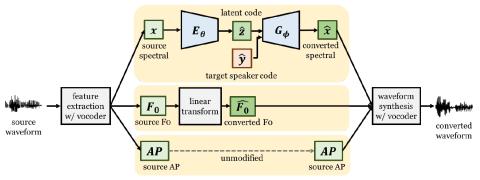
An effective approach for voice conversion (VC) is to disentangle linguistic content from other components in the speech signal. The effectiveness of variational autoencoder (VAE) based VC (VAE-VC), for instance, strongly relies on this principle. In our prior work, we proposed a cross-domain VAE-VC (CDVAE-VC) framework, which utilized acoustic features of different properties, to improve the performance of VAE-VC. We believed that the success came from more disentangled latent representations. In this paper, we extend the CDVAE-VC framework by incorporating the concept of adversarial learning, in order to further increase the degree of disentanglement, thereby improving the quality and similarity of converted speech. More specifically, we first investigate the effectiveness of incorporating the generative adversarial networks (GANs) with CDVAE-VC. Then, we consider the concept of domain adversarial training and add an explicit constraint to the latent representation, realized by a speaker classifier, to explicitly eliminate the speaker information that resides in the latent code. Experimental results confirm that the degree of disentanglement of the learned latent representation can be enhanced by both GANs and the speaker classifier. Meanwhile, subjective evaluation results in terms of quality and similarity scores demonstrate the effectiveness of our proposed methods.
Conclusions
In this paper, we have extended the cross-domain VAE based VC framework by integrating GANs and CLS into the training phase. The GAN objective was used to better approximate the distribution of real speech signals. The CLS, on the other hand, was applied to the latent code as an explicit constraint to eliminate speaker-dependent factors. Objective and subjective evaluations confirmed the effectiveness of the GAN and CLS objectives. We have also investigated the correlation between the degree of disentanglement and the conversion performance. A novel evaluation metric, DEM, that measures the degree of disentanglement in VC was derived. Experimental results confirmed a positive correlation between the degree of disentanglement and the conversion performance. In the future, we will exploit more acoustic features in the CDVAE system, including rawer features, such as the magnitude spectrum, and hand-crafted features, such as line-spectral pairs. An effective algorithm that can optimally determine the latent space dimension is also worthy of study. Finally, it is worthwhile to generalize this disentanglement framework to extract speaker-invariant latent representation from unknown source speakers in order to achieve many-to-one VC. We have made the source code publicly accessible so that readers can reproduce our results.