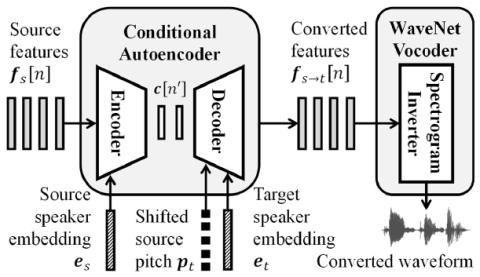
Non-parallel many-to-many voice conversion remains an interesting but challenging speech processing task. Many style-transfer-inspired methods such as generative adversarial networks (GANs) and variational autoencoders (VAEs) have been proposed. Recently, AutoVC, a conditional autoencoders (CAEs) based method achieved state-of-the-art results by disentangling the speaker identity and speech content using information-constraining bottlenecks, and it achieves zero-shot conversion by swapping in a different speaker's identity embedding to synthesize a new voice. However, we found that while speaker identity is disentangled from speech content, a significant amount of prosodic information, such as source F0, leaks through the bottleneck, causing target F0 to fluctuate unnaturally. Furthermore, AutoVC has no control of the converted F0 and thus unsuitable for many applications. In the paper, we modified and improved autoencoder-based voice conversion to disentangle content, F0, and speaker identity at the same time. Therefore, we can control the F0 contour, generate speech with F0 consistent with the target speaker, and significantly improve quality and similarity. We support our improvement through quantitative and qualitative analysis.
Conclusion
In this paper, we proposed an F0-conditioned voice conversion system that refreshes the previous state-of-the-art performance of AutoVC by eliminating any F0-related artifacts. It experimentally verified the hypothesis that any conditioned prosodic features can be disentangled from the input speech signal in an unsupervised manner by properly tuning the information-constraining bottleneck of a vanilla autoencoder. This could open a new path towards more detailed voice conversion by controlling different prosodic features.