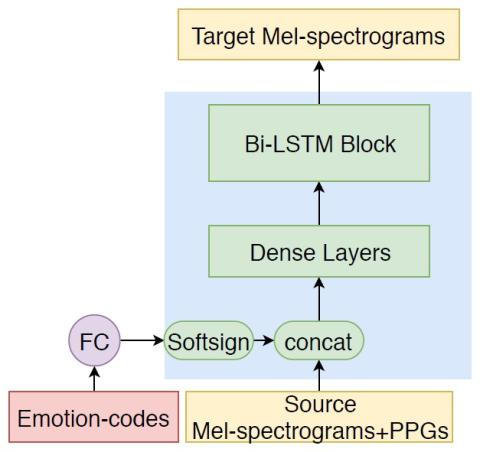
Emotional voice conversion (EVC) is one way to generate expressive synthetic speech. Previous approaches mainly focused on modeling one-to-one mapping, i.e., conversion from one emotional state to another emotional state, with Mel-cepstral vocoders. In this paper, we investigate building a multi-target EVC (MTEVC) architecture, which combines a deep bidirectional long-short term memory (DBLSTM)-based conversion model and a neural vocoder. Phonetic posteriorgrams (PPGs) containing rich linguistic information are incorporated into the conversion model as auxiliary input features, which boost the conversion performance. To leverage the advantages of the newly emerged neural vocoders, we investigate the conditional WaveNet and flow-based WaveNet (FloWaveNet) as speech generators. The vocoders take in additional speaker information and emotion information as auxiliary features and are trained with a multi-speaker and multi-emotion speech corpus. Objective metrics and subjective evaluation of the experimental results verify the efficacy of the proposed MTEVC architecture for EVC.
Conclusions
In this paper, we investigate building a multi-target EVC (MTEVC) architecture, which combines a DBLSTM-based conversion model and a neural vocoder. The target emotion is controlled by an emotion code. PPGs are regarded as auxiliary input features of the conversion model. To make use of multi-speaker and multi-emotion data for training, we study the feasibility of training the WaveNet and FloWaveNet models by incorporating two kinds of codes. Objective and subjective evaluations validate the effectiveness of the proposed approaches for MTEVC. The neural vocoder FloWaveNet, achieves the best spectral conversion performance for all emotion conversion pairs according to the objective metrics. Since the FloWaveNet model enables parallel audio signal generation and requires only a maximum likelihood loss for training, it deserves more investigation for better generation quality, which will be our future work.