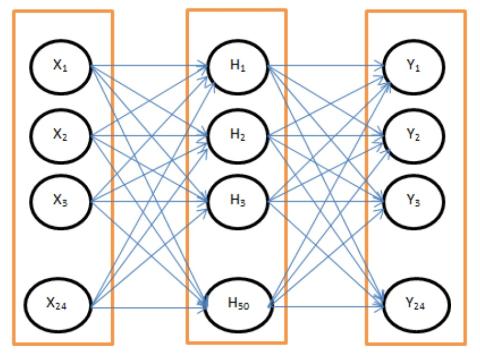
This research presents a neural network based voice conversion (VC) model. While it is a known fact that voiced sounds and prosody are the most important component of the voice conversion framework, what is not known is their objective contributions particularly in a noisy and uncontrolled environment. This model uses a 2-layer feedforward neural network to map the Linear prediction analysis coefficients of a source speaker to the acoustic vector space of the target speaker with a view to objectively determine the contributions of the voiced, unvoiced and supra-segmental components of sounds to the voice conversion model. Results showed that vowels “a”, “i”, “o” have the most significant contribution in the conversion success. The voiceless sounds were also found to be most affected by the noisy training data. An average noise level of 40 dB above the noise floor were found to degrade the voice conversion success by 55.14 percent relative to the voiced sounds. The result also shows that for cross-gender voice conversion, prosody conversion is more significant in scenarios where a female is the target speaker.
Conclusion
This work revealed the contribution of vowels and prosody in neural network based voice conversion model trained with noisy data. Most popular voice conversion models in literature use carefully selected training data obtained from trained voice experts and so the contribution of the speaker’s prosody and diction particularly in articulating the voiced and voiceless sounds were overlooked. This study revealed that for voice conversion models trained on samples recorded in uncontrolled noisy environment, the unvoiced sounds which are majorly consonant have more prominent roles to play. The study also revealed that in this kind of scenario, prosody conversion is even more important for male to female cross gender conversion. Further work would involve the study of the percentage contribution of all know voiced and unvoiced sound in the English language as these will be useful in situations where only very few training data are available or allowable for training purposes.