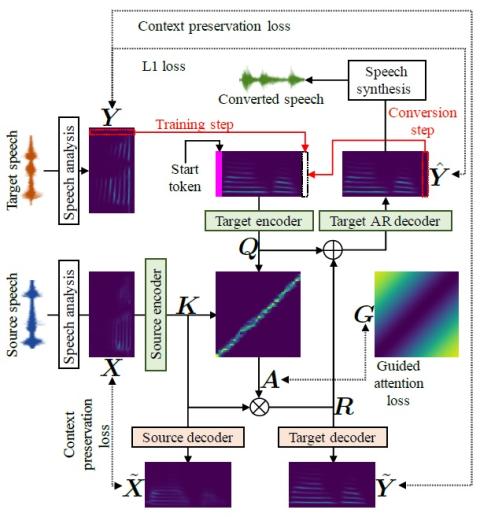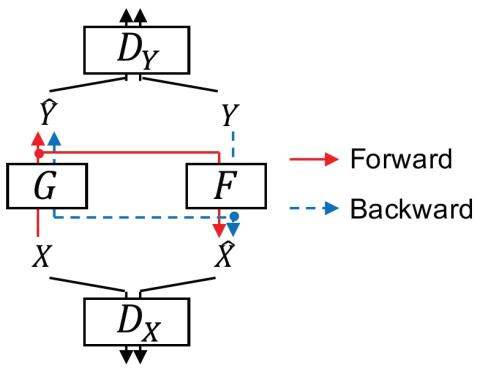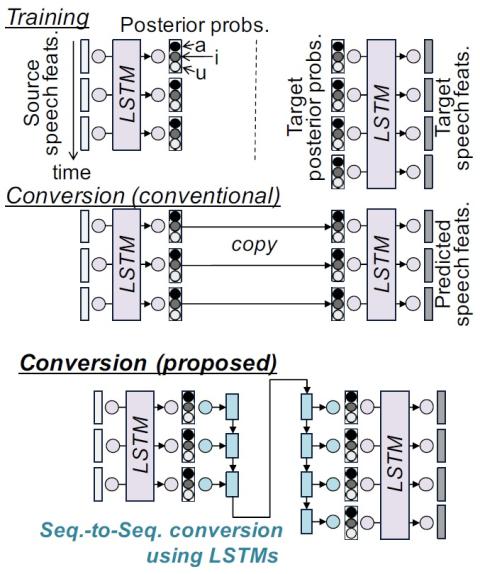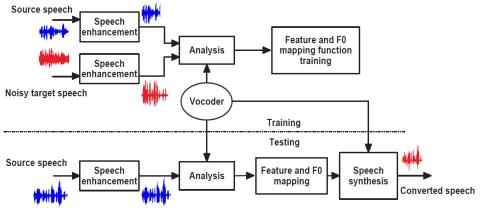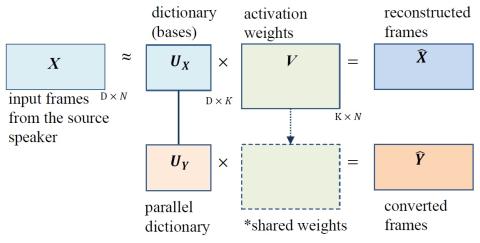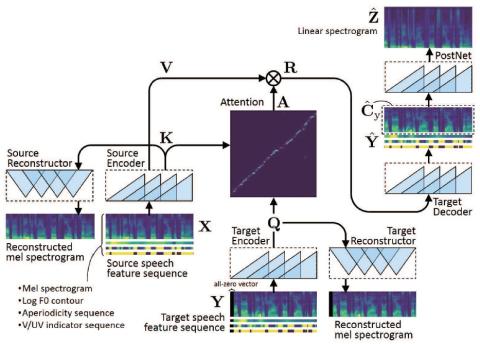
ConvS2S-VC: Полностью сверточное преобразование голоса из последовательности в последовательность
В этой статье предлагается метод преобразования голоса, основанный на полностью сверточном обучении от последовательности к последовательности (seq2seq). Настоящий метод, который мы называем "ConvS2S-VC", изучает соответствие между последовательностями речевых признаков источника и цели, используя полностью сверточную модель seq2seq с механизмом внимания. Из-за особенностей обучения seq2seq наш метод особенно примечателен тем, что он позволяет гибко преобразовывать не только характеристики голоса, но и контур высоты тона и продолжительность вводимой речи. Текущая модель состоит из шести сетей,...