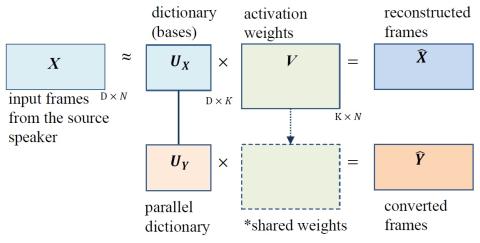
В этой статье мы предлагаем метод обновления словаря для неотрицательной матричной факторизации (NMF) с использованием многомерных данных в задаче спектрального преобразования (SC). Преобразование голоса широко изучалось из-за его потенциальных применений, таких как персонализированный синтез речи и улучшение качества речи. Основанный на примерах NMF (ENMF) представляется эффективным и, вероятно, самым простым выбором среди всех методов для SC, при условии, что предоставляется параллельный корпус исходной и целевой речи. SC-системы на основе ENMF обычно нуждаются в большом количестве баз (образцов) для обеспечения качества преобразованного голоса. Тем не менее, небольшой и эффективный словарь желателен, но его трудно получить с помощью обновления словаря, в частности, при использовании многомерных объектов, таких как ПРЯМЫЕ спектры. Поэтому мы предлагаем систему обновления словаря для NMF посредством переформулировки кодера-декодера. Использование NMF в качестве сети кодер-декодер позволяет более эффективно использовать весь параллельный корпус применительно к SC. Наши эксперименты демонстрируют значительные преимущества предлагаемой системы со словарями небольшого размера по сравнению с обычными системами на основе ENMF со словарями такого же или значительно большего размера.
Выводы
В этой статье представлена структура обновления словаря для спектрального преобразования на основе NMF путем переформулировки NMF как сети кодер-декодер. Преимущества этого метода двояки. Во-первых, предлагаемый метод позволяет избежать явного совместного обновления словаря, что удваивает размерность. Во-вторых, изученный словарь намного компактнее и обладает более высокой репрезентативной способностью, что приводит к улучшению качества передаваемой речи. Формулировка сети кодер-декодер может быть легко обобщена на случаи применения без ограничения неотрицательности. Мы рассмотрим эти случаи в будущем.