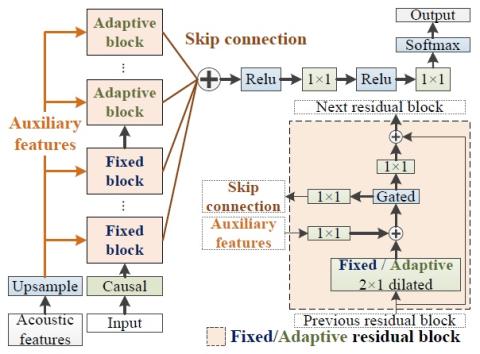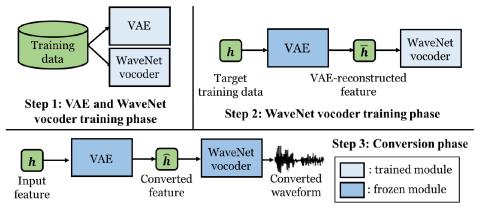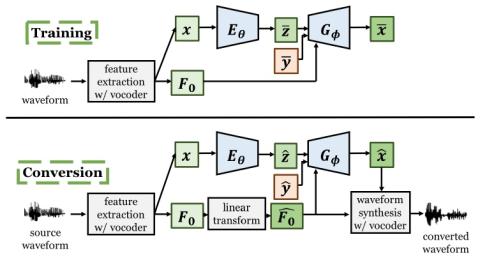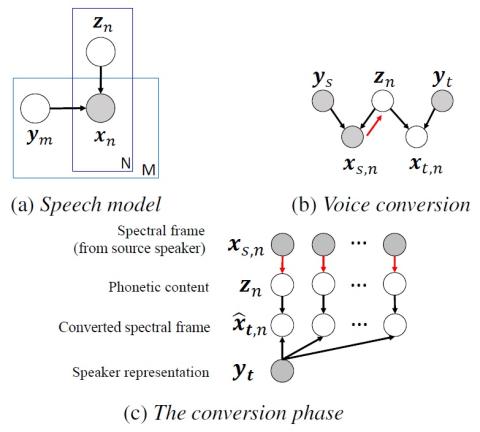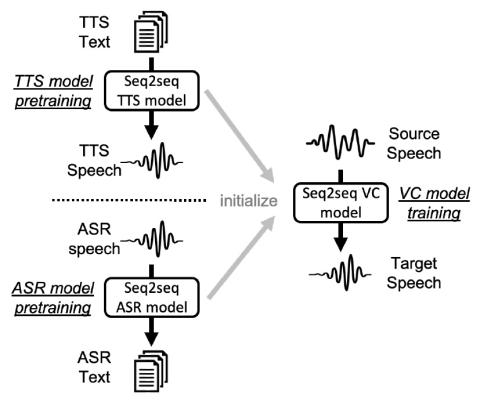
Методы предварительной подготовки для преобразования голоса из последовательности в последовательность
Модели преобразования голоса (VC) из последовательности в последовательность (seq2seq) привлекательны благодаря своей способности преобразовывать просодию. Тем не менее, без достаточных данных модели seq2seq преобразования голоса могут страдать от нестабильного обучения и проблем с неправильным произношением в преобразованной речи, что далеко не практично. Чтобы устранить эти недостатки, мы предлагаем перенести знания из других задач обработки речи, где легко доступны крупномасштабные базы данных, как правило, преобразование текста в речь (TTS) и автоматическое распознавание речи (ASR). Мы утв...