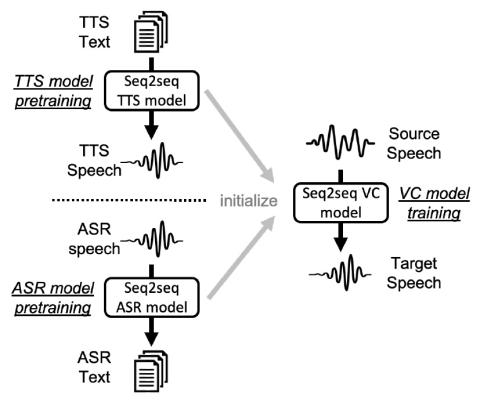
Модели преобразования голоса (VC) из последовательности в последовательность (seq2seq) привлекательны благодаря своей способности преобразовывать просодию. Тем не менее, без достаточных данных модели seq2seq преобразования голоса могут страдать от нестабильного обучения и проблем с неправильным произношением в преобразованной речи, что далеко не практично. Чтобы устранить эти недостатки, мы предлагаем перенести знания из других задач обработки речи, где легко доступны крупномасштабные базы данных, как правило, преобразование текста в речь (TTS) и автоматическое распознавание речи (ASR). Мы утверждаем, что модели преобразования голоса инициализированные такими предварительно обученными параметрами модели ASR или TTS, могут генерировать эффективные скрытые представления для получения высокоточной, очень разборчивой преобразованной речи. Мы применяем такие методы к моделям, основанным на рекуррентных нейронных сетях (RNN) и трансформаторах, и с помощью систематических экспериментов демонстрируем эффективность схемы предварительного обучения и превосходство моделей, основанных на трансформаторах, над моделями, основанными на RNN, с точки зрения понятности, естественности и сходства.
Выводы
В этой работе мы оценили методы предварительного обучения для решения проблемы эффективности обработки данных в seq2seq преобразовании голоса. В частности, была предложена унифицированная двухэтапная стратегия обучения, которая сначала предварительно тренирует декодер и кодировщик, а затем инициализирует модель преобразования голоса параметрами предварительно обученной модели. ASR и TTS были выбраны в качестве исходных задач для передачи знаний, и были реализованы архитектуры RNN и VTN. С помощью объективных и субъективных оценок было показано, что стратегия предварительного обучения TTS может значительно улучшить производительность с точки зрения разборчивости и качества речи при применении как к RNN, так и к VTN, и производительность может оставаться без существенного ухудшения даже при ограниченных данных обучения. Что касается предварительной подготовки ASR, то надежность была не столь высока из-за уменьшения размера обучающих данных. Кроме того, результаты VTN были хуже, чем у RNN без предварительной тренировки, но лучше с предварительной тренировкой TTS. Эксперимент с визуализацией показал, что предварительное обучение TTS может освоить богатое лингвистической информацией пространство скрытой репрезентации, в то время как предварительное обучение ASR лишено такой способности, что позволяет нам представить, каким было бы идеальное пространство скрытой репрезентации.
В будущем мы планируем распространить нашу методику предварительной подготовки на более гибкие условия тренировок, такие как тренировка "многие ко многим" или непараллельная тренировка.