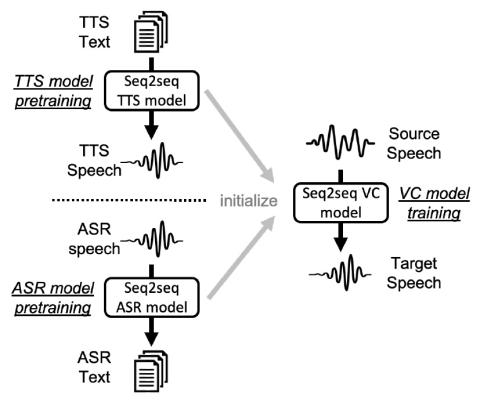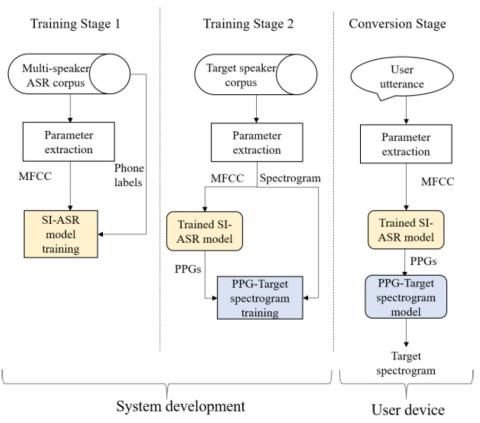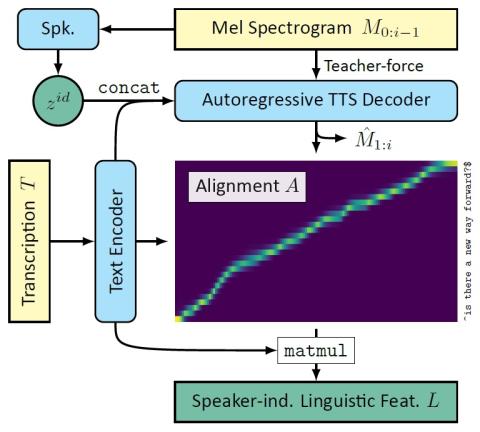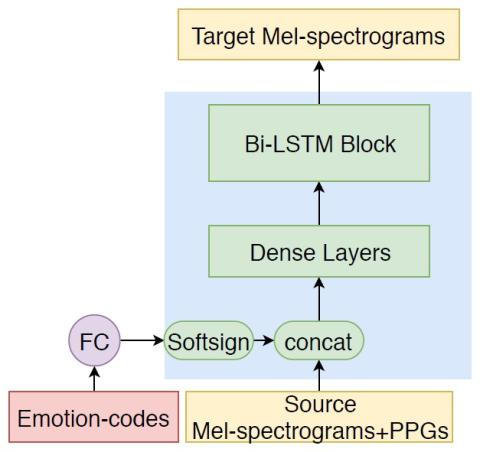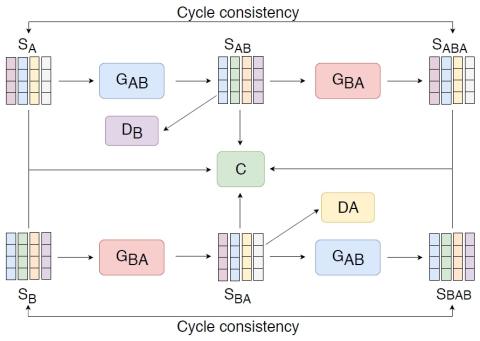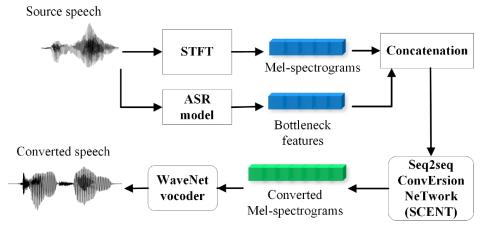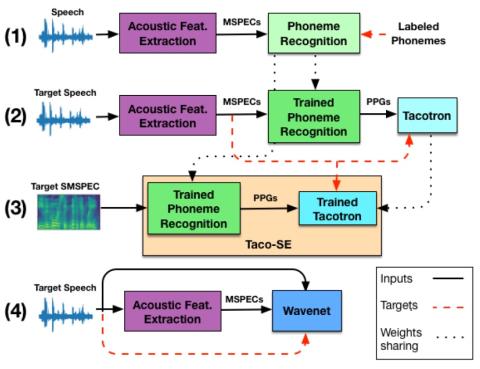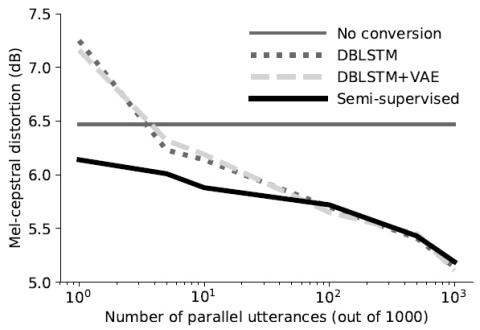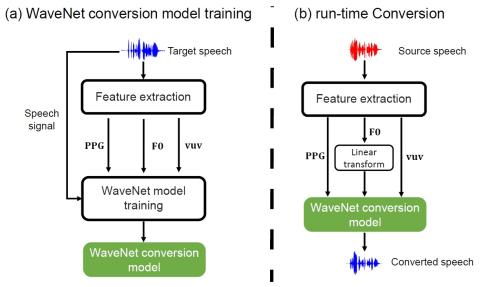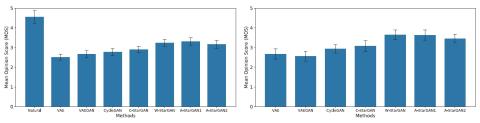
Непараллельное преобразование голоса с дополненным классификатором звездных генеративных состязательных сетей
Ранее мы предложили метод, который позволяет осуществлять непараллельное преобразование голоса (VC) с использованием варианта генеративных состязательных сетей (GANS) под названием StarGAN. Основные особенности нашего метода, получившего название StarGAN-VC, заключаются в следующем. Во-первых, он не требует параллельных высказываний, транскрипций или процедур выравнивания времени для тренировки генератора речи. Во-вторых, он может одновременно изучать сопоставления между несколькими доменами, используя единую генераторную сеть, чтобы в полной мере использовать доступные обучающие данные, собра...