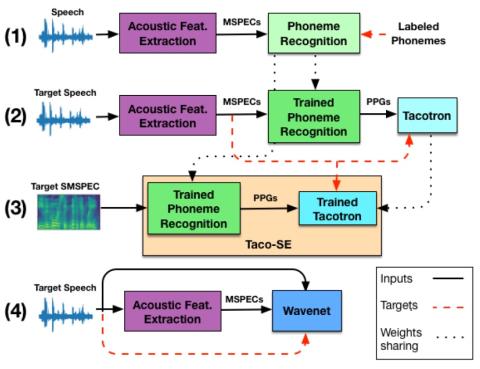
В этой статье представлена Taco-VC, новая архитектура преобразования голоса, основанная на синтезаторе Tacotron, которая представляет собой модель последовательного преобразования голоса с учетом внимания. Обучение систем преобразования голоса с несколькими динамиками требует большого объема ресурсов, как в плане обучения, так и в плане размера корпуса. Taco-VC реализован с использованием синтезатора Tacotron с одним говорящим, основанного на фонетических апостериограммах (PPG), и вокодера Wavenet с одним говорящим, основанного на спектрограммах Mel. Для повышения качества преобразованной речи выходные данные Tacotron передаются через новую сеть улучшения речи, которая состоит из комбинации сетей распознавания фонем и Tacotron. Наша система обучается только на одном корпусе носителей среднего размера и адаптируется к новым носителям, используя всего несколько минут обучающих данных. Используя общедоступные наборы данных среднего размера, наш метод превосходит базовый уровень в задаче VCC 2018 SPEAK и обеспечивает конкурентоспособные результаты по сравнению с сетями с несколькими говорящими, обученными на частных больших наборах данных.
Вывод
В этой статье представлена Taco-VC, система преобразования голоса, состоящая из распознавания фонем, синтезатора Tacotron и вокодера Wavenet. Мы представляем сеть улучшения речи, которая может представлять интерес сама по себе, и описываем, как улучшить синтезированные Mel-спектрограммы, используя только обученные сети. В экспериментах с MOS мы показали, что наша архитектура, использующая общедоступные обучающие наборы с одним говорящим среднего размера, может адаптироваться к другим целям с ограниченными обучающими наборами, использующими только одну акустическую систему, и обеспечивать конкурентоспособные результаты по сравнению с системами преобразования голоса с несколькими говорящими, обученными на частных и гораздо более крупных наборах данных.
Мы считаем, что высокая частота ошибок в сети распознавания фонем оказывает большое влияние на преобразуемую речь. В качестве будущей работы мы предлагаем добавить дополнительные акустические функции к сгенерированным PPG-файлам, таким как F0 и голосовой / невокализованный флаг, или извлечь PPG-файлы из других сетей распознавания речи с более низкой частотой ошибок. Кроме того, наши результаты показывают, что обучение одной женщины-диктора может оказаться недостаточным для адаптации к задачам мужского пола. Поэтому в данном случае может оказаться полезным дополнительное обучение одного мужчины-диктора. Возможно, в будущей работе было бы целесообразно также изучить влияние потерь из-за конкуренции на нашу систему. Другим возможным направлением будущих исследований является применение архитектуры Taco-SE (с соответствующим вейвлетом для снижения шума) к задачам снижения шума речи.