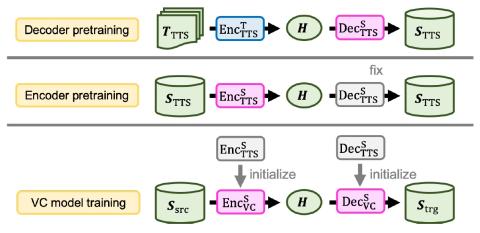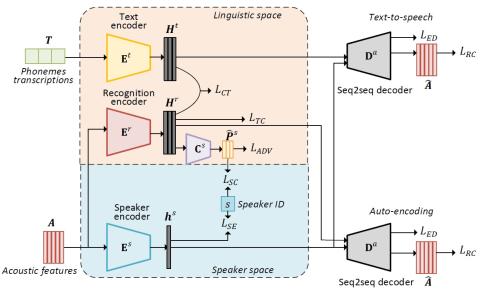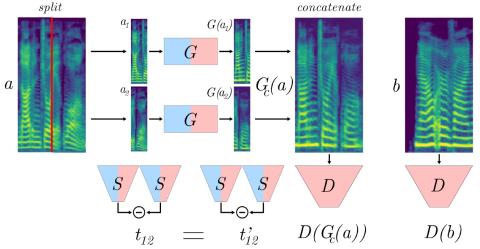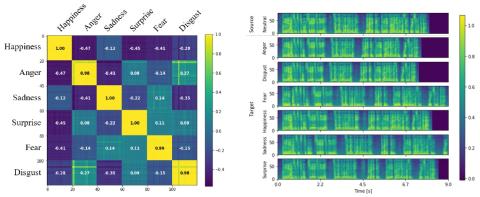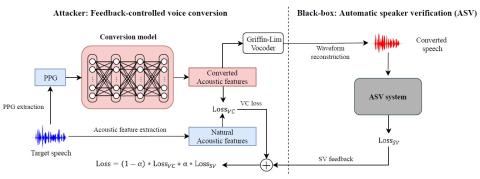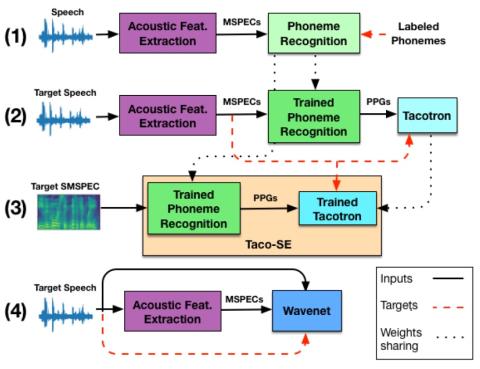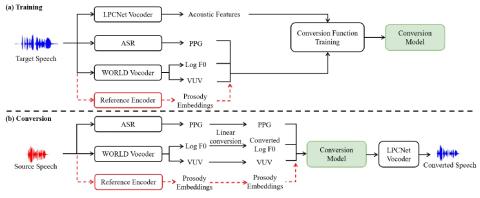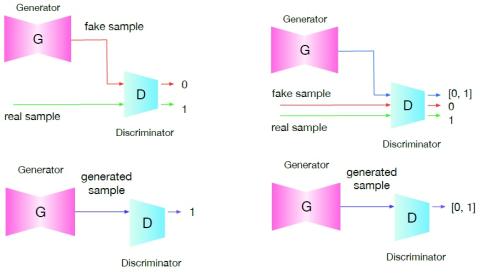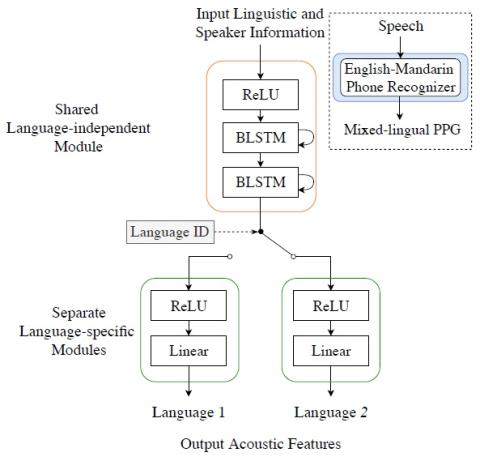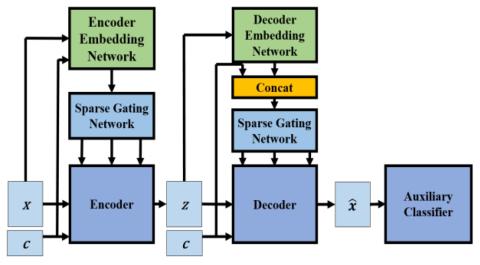
MoEVC: Система преобразования голоса, созданная экспертами, с механизмом разреженного стробирования для ускорения онлайн-вычислений
Благодаря последним достижениям в области технологий глубокого обучения производительность преобразования голоса с точки зрения качества и сходства была значительно улучшена. Однако для систем преобразования голоса на основе глубокого обучения, как правило, требуются большие объемы вычислений, что может привести к значительным задержкам и, таким образом, ограничить их применение в реальных приложениях. Поэтому повышение эффективности онлайн-вычислений стало важной задачей. В этом исследовании мы предлагаем новую систему преобразования голоса, основанную на сотрудничестве экспертов (MoE). Модел...