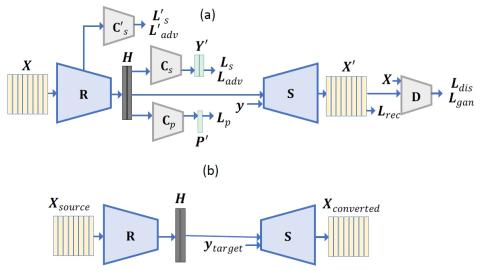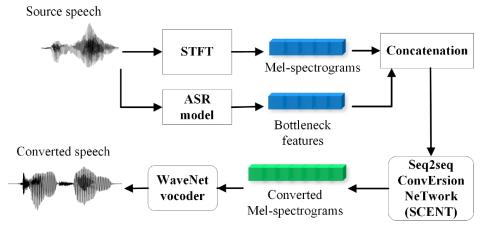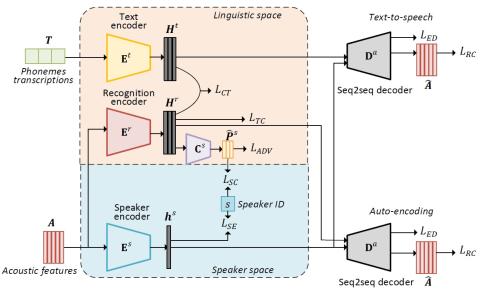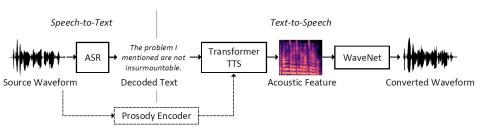
Преобразование голоса с помощью каскадного автоматического распознавания речи и преобразования текста в речь с передачей просодии
С развитием технологий автоматического распознавания речи (ASR) и синтеза текста в речь (TTS) стало интуитивно понятно построить систему преобразования голоса путем каскадного подключения систем ASR и TTS. В этой статье мы представляем метод ASR-TTS для преобразования голоса, в котором используется механизм iFLYTEK ASR для преобразования исходной речи в текст и модель Transformer TTS с вокодером WaveNet для синтеза преобразованной речи из декодированного текста. Для модели TTS мы предложили использовать код просодии для описания просодической информации, отличной от текста и информации о дикто...