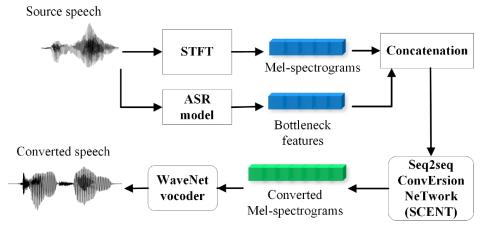
В этой статье представлена нейронная сеть под названием Sequence-to-sequence ConvErsion NeTwork (SCENT) для акустического моделирования в преобразовании голоса. На этапе обучения модель SCENT оценивается путем неявного сопоставления последовательностей признаков исходного и целевого говорящих, используя механизм внимания. На этапе преобразования акустические характеристики и длительность исходных звуков преобразуются одновременно с использованием единой акустической модели. В качестве акустических характеристик используются спектрограммы в масштабе Mel, которые содержат описания речевых сигналов как возбуждения, так и речевого тракта. Характерные особенности, выделенные из исходной речи с использованием модели автоматического распознавания речи (ASR), добавляются в качестве вспомогательных входных данных. Вокодер WaveNet, основанный на Mel-спектрограммах, предназначен для восстановления сигналов на основе выходных данных модели SCENT. Стоит отметить, что предлагаемый нами метод позволяет добиться соответствующего преобразования длительности, что затруднительно при использовании традиционных методов. Экспериментальные результаты показывают, что предложенный нами метод показал лучшую объективную и субъективную эффективность, чем базовые методы, использующие модели гауссовой смеси (GMM) и глубокие нейронные сети (DNN) в качестве акустических моделей. Этот предложенный метод также превзошел результаты нашей предыдущей работы, которая заняла первое место в конкурсе Voice Conversion Challenge 2018. Тесты на абляцию также подтвердили эффективность нескольких компонентов предложенного нами метода.
Вывод
В этой статье представлен SCENT - последовательная нейронная сеть для акустического моделирования преобразования голоса. В качестве акустических характеристик используются Mel-спектрограммы. Характеристики узких мест, выделенные с помощью модели ASR, используются в качестве дополнительных лингвистических описаний и объединяются с исходными акустическими характеристиками в качестве входных данных сети. Используя преимущества механизма внимания, модель SCENT не зависит от предварительной обработки выравнивания DTW, и преобразование длительности может быть выполнено одновременно. Наконец, преобразованные акустические характеристики передаются через вокодер WaveNet для восстановления речевых сигналов. Объективные и субъективные результаты экспериментов продемонстрировали превосходство предложенного нами метода по сравнению с базовыми методами, особенно в аспекте продолжительности. Тесты на абляцию еще раз подтвердили преимущества ввода Mel-спектрограмм и необходимость использования функций "узкого места". Важность модуля "внимания" и положительный эффект кода местоположения также были доказаны в ходе наших исследований по абляции. В будущем мы планируем исследовать влияние размера обучающей выборки на эффективность предлагаемого нами метода и уменьшить ошибки преобразования за счет улучшения расчета внимания.