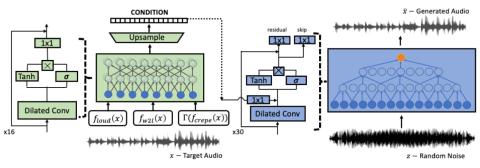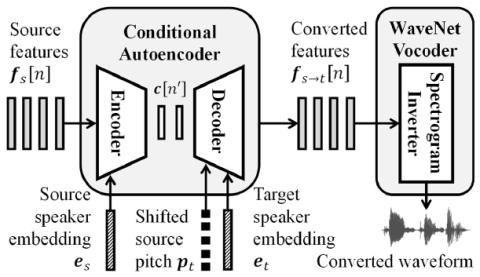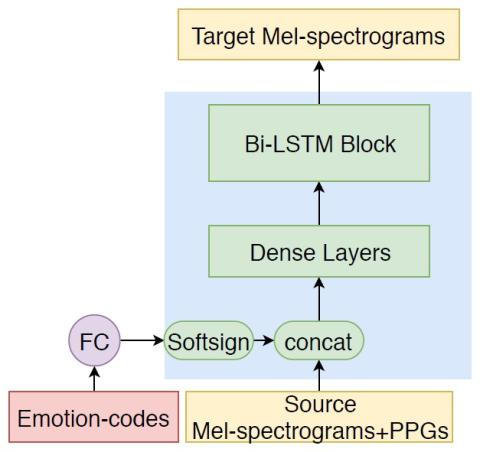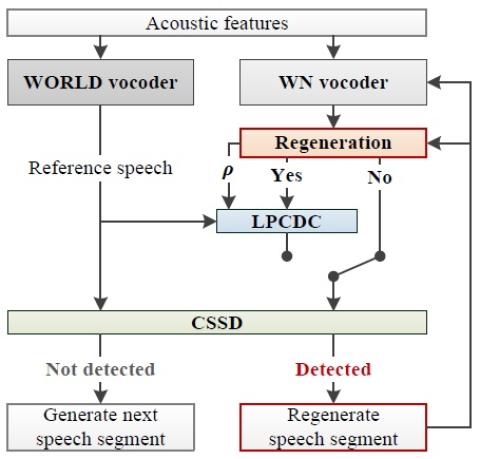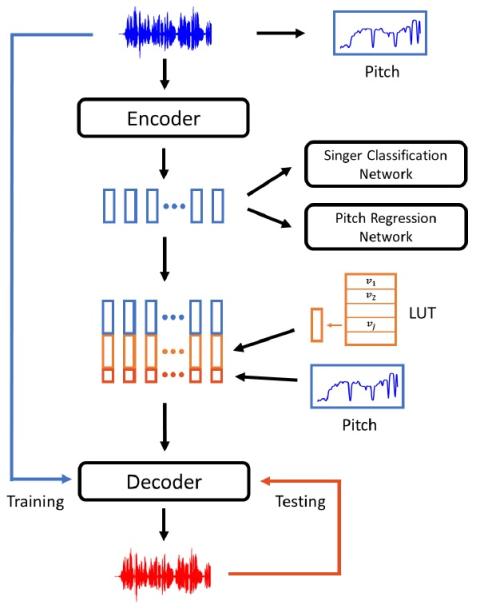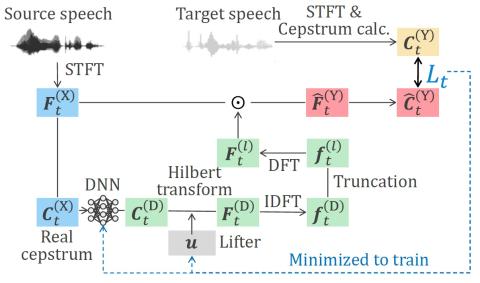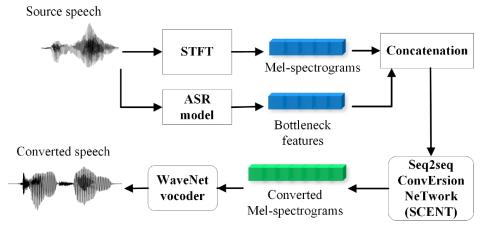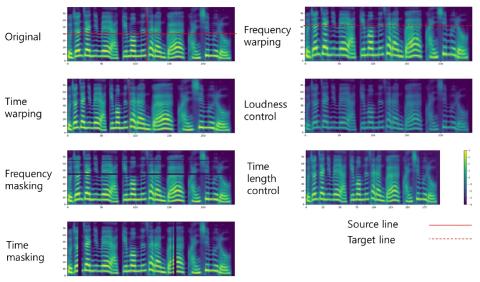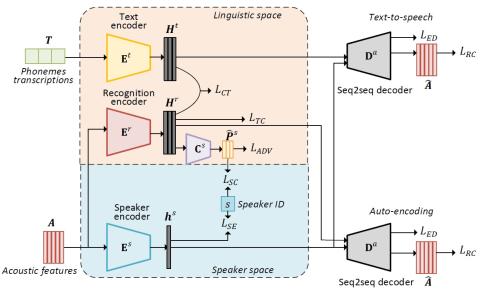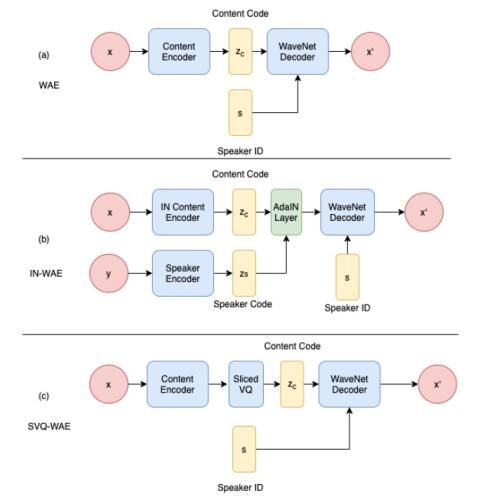
Обучение представлению неконтролируемых акустических блоков для преобразования голоса с использованием автокодеров WaveNet
В последние годы изучение речи без присмотра представляет большой интерес, что, например, проявляется в широком интересе к задачам ZeroSpeech. В этой работе представлен новый метод обучения представлений уровня кадров на основе автокодеров WaveNet. Особый интерес в конкурсе "ZeroSpeech Challenge 2019" представляли модели с дискретной скрытой переменной, такие как векторно-квантованный вариационный автокодер (VQVAE). Однако эти модели генерируют речь с относительно низким качеством. В этой работе мы стремимся решить эту проблему с помощью двух подходов: во-первых, WaveNet используется в качеств...