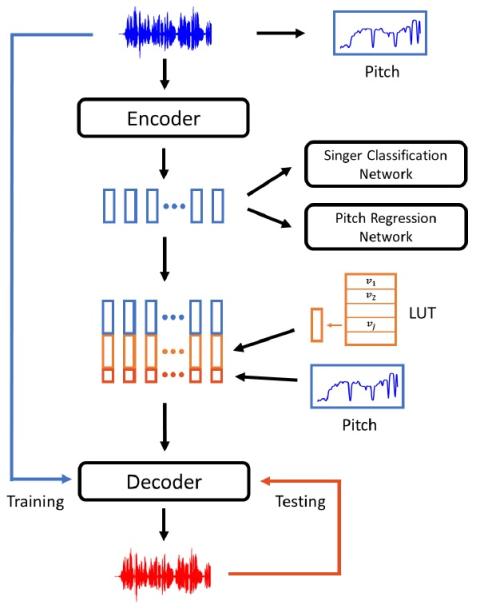
Преобразование певческого голоса заключается в преобразовании голоса певца в голос другого человека без изменения содержания пения. Недавняя работа показывает, что преобразование певческого голоса без контроля может быть достигнуто с помощью подхода, основанного на автоэнкодировании [1]. Однако преобразованный певческий голос может легко сбиться с тональности, что свидетельствует о том, что существующий подход не позволяет точно моделировать информацию о высоте тона. В этой статье мы предлагаем усовершенствовать существующий метод преобразования певческого голоса без контроля, предложенный в [1], для достижения более точной передачи высоты тона и гибкого управления высотой тона. В частности, в предлагаемую PitchNet была добавлена обучаемая с помощью состязательных методов сеть регрессии высоты тона, чтобы заставить сеть кодировщика изучать фонемное представление, не зависящее от высоты тона, и отдельный модуль для передачи высоты тона, извлеченного из исходного аудио, в сеть декодера. Наша оценка показывает, что предложенный метод может значительно улучшить качество преобразованного певческого голоса (2,92 против 3,75 в MOS). Мы также демонстрируем, что высотой преобразованного пения можно легко управлять во время генерации, изменяя уровни извлеченной высоты звука перед передачей его в сеть декодера.
Вывод
В этой статье предлагается новый метод преобразования голоса певца без сопровождения, получивший название PitchNet. Сеть регрессии высоты тона используется для отображения противоречивых потерь, отделяющих информацию, связанную с высотой тона, от скрытого пространства в автоэнкодере. После работы кодера, подобного WaveNet, генерируется представление, инвариантное к исполнителю и высоте тона, которое затем передается в декодер WaveNet, который использует встроенную информацию о певце и извлеченную высоту тона для восстановления целевого певческого голоса. Наш метод превосходит существующие методы преобразования голоса певца без присмотра и обеспечивает гибкую настройку высоты тона.