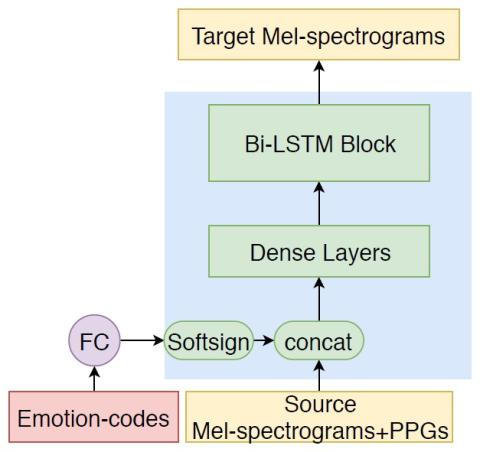
Преобразование эмоционального голоса (EVC) - это один из способов создания выразительной синтетической речи. Предыдущие подходы в основном были сосредоточены на моделировании взаимно однозначного отображения, т.е. перехода из одного эмоционального состояния в другое эмоциональное состояние, с помощью мелкополосных вокодеров. В этой статье мы исследуем построение многоцелевой архитектуры EVC (MTEVC), которая сочетает в себе модель преобразования на основе глубокой двунаправленной долговременной памяти (DBLSTM) и нейронный вокодер. Фонетические апостериограммы (PPG), содержащие богатую лингвистическую информацию, включаются в модель преобразования в качестве вспомогательных функций ввода, которые повышают производительность преобразования. Чтобы использовать преимущества недавно появившихся нейронных вокодеров, мы исследуем условную волновую сеть и потоковую волновую сеть (FloWaveNet) в качестве генераторов речи. Вокодеры принимают дополнительную информацию о говорящем и информацию об эмоциях в качестве вспомогательных функций и обучаются с использованием речевого корпуса с несколькими дикторами и несколькими эмоциями. Объективные показатели и субъективная оценка результатов эксперимента подтверждают эффективность предложенной архитектуры MTEVC для EVC.
Выводы
В этой статье мы исследуем построение многоцелевой архитектуры AVC (MVC), которая сочетает в себе модель преобразования на основе DBLSTM и нейронный вокодер. Целевая эмоция контролируется эмоциональным кодом. PPG рассматриваются как вспомогательные входные параметры модели преобразования. Чтобы использовать данные с несколькими динамиками и несколькими эмоциями для обучения, мы изучаем возможность обучения моделей WaveNet и FloWaveNet путем включения двух видов кодов. Объективные и субъективные оценки подтверждают эффективность предлагаемых подходов к MTEVC. Нейронный вокодер FloWaveNet обеспечивает наилучшую производительность спектрального преобразования для всех пар преобразования эмоций в соответствии с объективными показателями. Поскольку модель FloWaveNet обеспечивает параллельную генерацию аудиосигнала и требует только потери максимального правдоподобия для обучения, она заслуживает дальнейшего изучения для улучшения качества генерации, что станет нашей будущей работой.