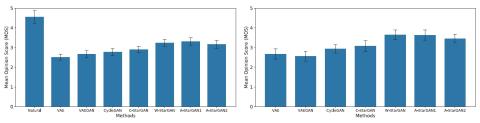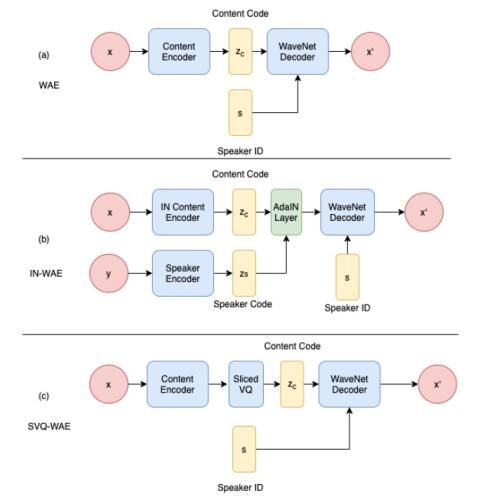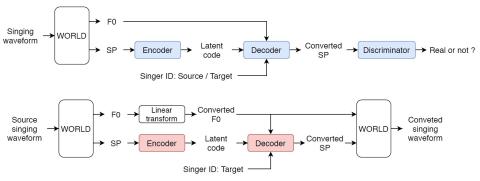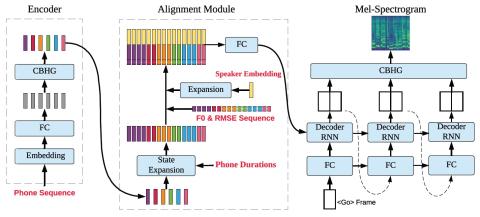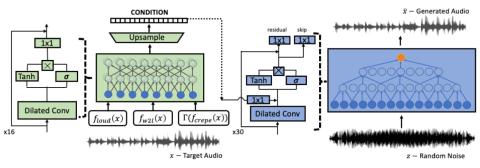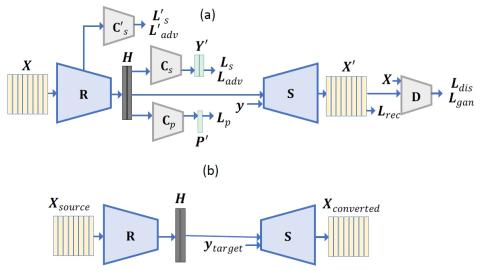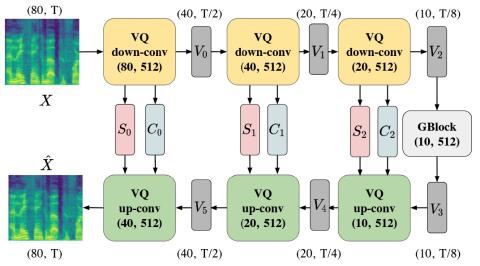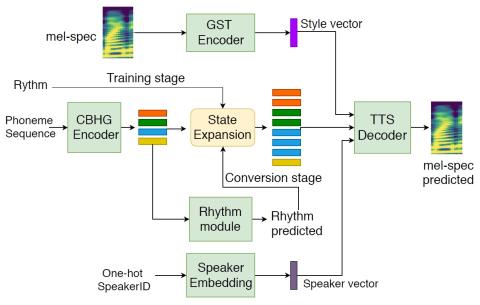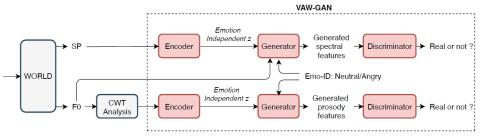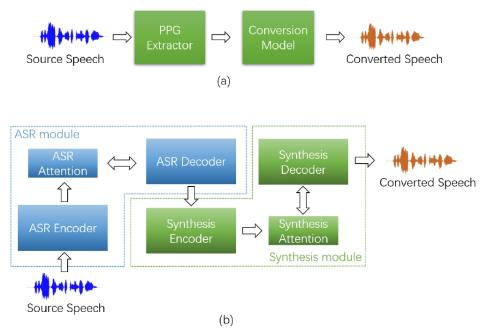
Преобразование голоса от любого ко многим с моделированием с относительным местоположением от последовательности к последовательности
В этой статье предлагается подход к непараллельному преобразованию голоса от любого ко многим относительно местоположения, от последовательности к последовательности (seq2seq), который использует контроль текста во время обучения. В этом подходе мы объединяем экстрактор функций бутылочного горлышка (BNE) с модулем синтеза seq2seq. На этапе обучения обучается гибридный распознаватель фонем коннекционист-временная классификация-внимание (CTC-attention) на основе кодера-декодера, кодер которого имеет слой горлышка бутылки. BNE получается из распознавателя фонем и используется для извлечения незав...