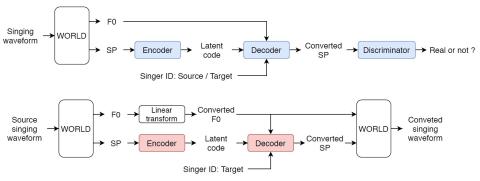
Преобразование голоса певца направлено на преобразование голоса певца из исходного в целевой без изменения содержания пения. Данные параллельного обучения обычно требуются для обучения системы преобразования певческого голоса, что, однако, непрактично в реальных приложениях. Новейшие структуры кодер-декодер, такие как вариационная автоэнкодирующая генеративно-состязательная сеть Вассерштейна (VAW-GAN), обеспечивают эффективный способ изучения отображения с помощью непараллельных обучающих данных. В этой статье мы предлагаем фреймворк преобразования певческого голоса, основанный на VAW-GAN. Мы обучаем кодировщик отделять личность певца и просодию пения (контур F0) от фонетического содержания. Настраивая идентификатор исполнителя и F0, декодер генерирует выходные спектральные характеристики с невидимой идентификацией целевого исполнителя и улучшает рендеринг F0. Экспериментальные результаты показывают, что предлагаемая структура обеспечивает более высокую производительность, чем базовые структуры.
Вывод
В этой статье мы предлагаем фреймворк преобразования певческого голоса без параллельных данных с помощью VAW-GAN. Сначала мы предлагаем провести независимое от певца обучение с использованием процесса кодирования-декодирования. Мы также предлагаем установить условие F0 в декодере, чтобы улучшить производительность преобразования пения. Мы устраняем необходимость в параллельном обучении данных или других процедурах выравнивания по времени и достигаем высокой производительности преобразованных певческих голосов. Экспериментальные результаты показывают эффективность предложенной нами структуры SVC как для внутригендерного, так и для межгендерного преобразования певческого голоса.