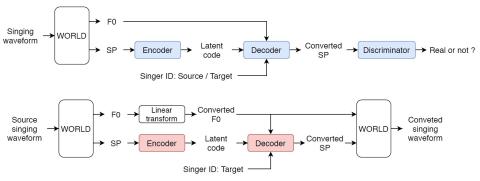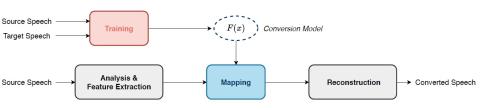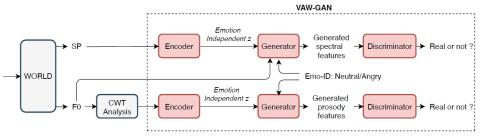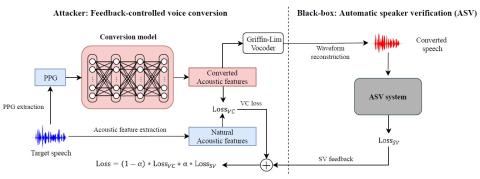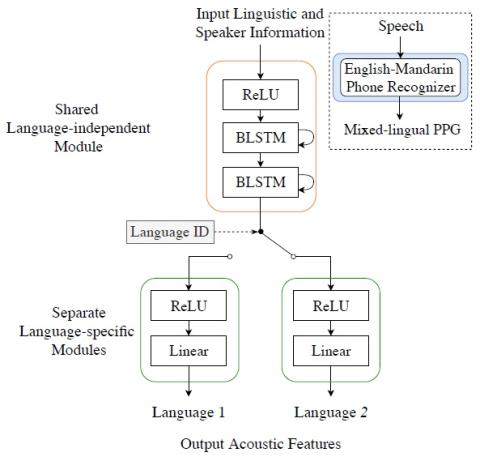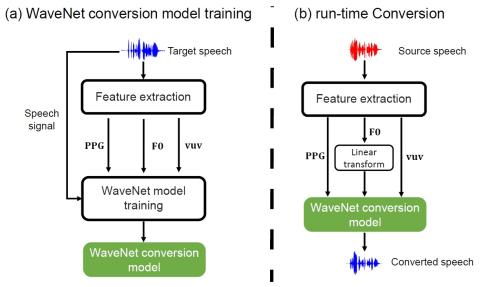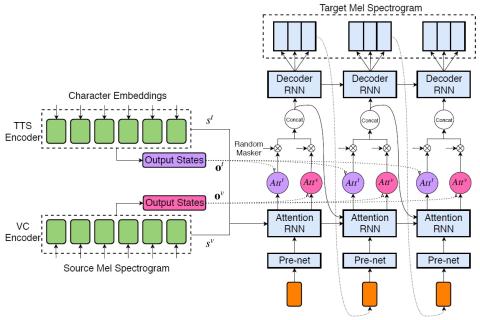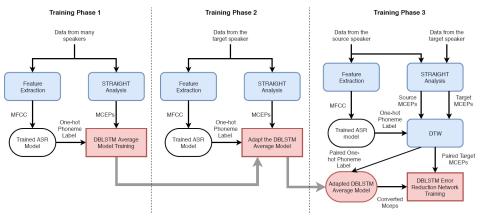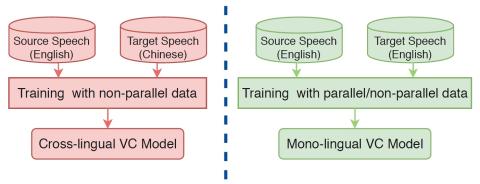
Преобразование спектра и просодии для межъязыкового преобразования голоса с помощью CycleGAN
Межъязыковое преобразование голоса направлено на изменение голоса говорящего источника, чтобы он звучал так же, как у целевого говорящего, когда исходные и целевые говорящие говорят на разных языках. Он основан на непараллельных данных обучения с двух разных языков, следовательно, является более сложным, чем преобразование голоса на одном языке. Предыдущие исследования по межъязыковому преобразованию голоса в основном фокусировались на спектральном преобразовании с линейным преобразованием для передачи F0. Однако, как важный просодический фактор, F0 по своей сути является иерархическим, поэтом...