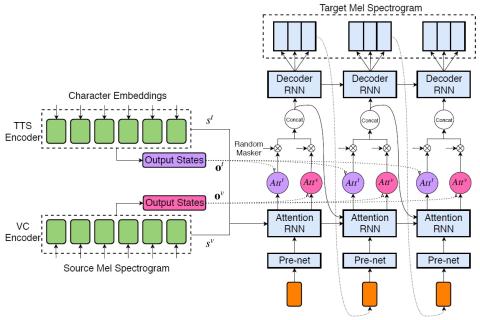
Мы исследовали процесс обучения общей модели как для задач преобразования текста в речь, так и для задач преобразования голоса. Мы предлагаем использовать архитектуру расширенной модели Tacotron, которая представляет собой модель последовательного преобразования из нескольких источников с механизмом двойного внимания, в качестве общей модели как для задач преобразования текста в речь, так и для задач преобразования голоса. Эта модель может выполнять эти две различные задачи соответственно в зависимости от типа входных данных. Задача сквозного синтеза речи выполняется, когда модели в качестве входных данных задается текст, в то время как задача преобразования голоса из последовательности в последовательность выполняется, когда в качестве входных данных задается речь диктора-источника. Звуковые сигналы генерируются с помощью WaveNet, который настраивается с помощью прогнозируемой mel-спектрограммы. Мы предлагаем совместно обучить общую модель декодированию для целевого диктора, которая поддерживает несколько источников. Эксперименты с прослушиванием показывают, что предложенная нами модель кодера-декодера с несколькими источниками может эффективно выполнять задачи преобразования текста в речь и преобразования голоса.
Заключение и дальнейшая работа
В этой статье мы предложили совместную модель как для задач преобразования текста в речь, так и для задач преобразования голоса. Архитектура нашей модели основана на Tacotron. Учитывая текстовые символы в качестве входных данных, модель выполняет сквозной синтез речи. Учитывая спектрограмму диктора-источника, модель выполняет преобразование голоса из последовательности в последовательность. Результаты экспериментов показали, что предложенная нами модель позволяет выполнять задачи преобразования текста в речь и преобразования голоса, а также повышает производительность преобразования голоса по сравнению с автономной моделью. Наша будущая работа будет заключаться в поиске лучшего метода маскировки входных кодеров и более подходящего алгоритма обучения.