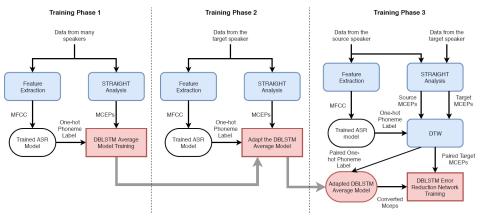
На данный момент многие подходы к глубокому обучению для преобразования голоса позволяют получать речь хорошего качества, используя большое количество обучающих данных. В этой статье представлена платформа преобразования голоса на основе глубокой двунаправленной долговременной памяти (DBLSTM), которая может работать с ограниченным количеством обучающих данных. Мы предлагаем реализовать усредненную модель на основе DBLSTM, которая обучается на данных от многих дикторов. Затем мы предлагаем выполнить адаптацию с ограниченным количеством целевых данных. И последнее, но не менее важное: мы предлагаем сеть уменьшения ошибок, которая может еще больше улучшить качество преобразования голоса. Предлагаемая структура основана на трех наблюдениях. Во-первых, DBLSTM может добиться замечательного преобразования голоса, учитывая долгосрочные зависимости речевого высказывания. Во-вторых, усредненная модель, основанная на DBLSTM, может быть легко адаптирована с использованием небольшого объема данных для получения речи, которая звучит ближе к цели. В-третьих, сеть по уменьшению ошибок может быть обучена с помощью небольшого объема обучающих данных и может эффективно улучшить качество преобразования. Эксперименты показывают, что предложенная система преобразования голоса является гибкой для работы с ограниченными обучающими данными и превосходит традиционные системы как в объективных, так и в субъективных оценках
Выводы
В этой статье представлена сеть уменьшения ошибок для адаптированного подхода к преобразованию голоса на основе DBLSTM, который позволяет достичь хорошей производительности при ограниченном количестве параллельных данных от исходного диктора и целевого диктора. Во-первых, мы предлагаем обучить усредненную модель для обозначения одной фонемы, чтобы сопоставить MCEPs с данными от многих носителей, исключая говорящего-источника и целевого носителя. Затем мы предлагаем адаптировать усредненную модель к ограниченному количеству целевых данных. Кроме того, мы внедряем систему уменьшения ошибок, которая позволяет улучшить качество преобразования голоса. Результаты экспериментов, как объективных, так и субъективных, показывают, что предлагаемый нами подход может эффективно использовать ограниченные данные и превосходит базовый подход. В будущем мы изучим возможность использования вокодера WaveNet, представляющего собой сверточную нейронную сеть, которая может генерировать необработанный звуковой сигнал выборку за выборкой, чтобы улучшить качество и естественность преобразованной речи. Некоторые образцы для теста на прослушивание доступны по этой ссылке: https://arkhamimp.github.io/ErrorReductionNetwork/