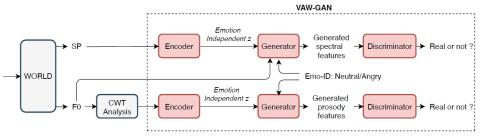
Эмоциональное преобразование голоса направлена на преобразование эмоции речи из одного состояния в другое при сохранении языкового содержания и идентичности говорящего. Предыдущие исследования по эмоциональному преобразованию голоса в основном проводились в предположении, что эмоции зависят от говорящего. Мы считаем, что эмоции выражаются универсально у всех говорящих, поэтому возможно независимое от говорящего отображение эмоциональных состояний речи. В этой статье мы предлагаем построить независимую от диктора структуру эмоционального преобразования голоса, которая может конвертировать любые эмоции без необходимости параллельных данных. Мы предлагаем структуру кодера-декодера на основе VAW-GAN для изучения спектрального и просодического отображения. Мы выполняем преобразование просодии с помощью непрерывного вейвлет-преобразования (CWT) для моделирования временных зависимостей. Мы также исследуем использование F0 в качестве дополнительного входа в декодер для повышения производительности преобразования эмоций. Эксперименты показывают, что предложенная независимая от диктора структура обеспечивает конкурентные результаты как для видимых, так и для невидимых дикторов.
Выводы
В этой статье мы предлагаем независимую от диктора систему эмоционального преобразования голоса, которая преобразует эмоции любого человека без необходимости параллельного обучения. Мы выполняем как спектральное, так и просодическое преобразование на основе VAW-GAN. Мы предлагаем CWT-моделирование F0 для описания просодии в различных временных разрешениях. Кроме того, мы изучаем использование основанного на CWT F0 в качестве дополнительного входа в декодер для повышения производительности преобразования спектра. Экспериментальные результаты подтверждают идею независимого от диктора преобразования эмоций, демонстрируя замечательную производительность как для видимых, так и для невидимых дикторов.
Это исследование подчеркивает необходимость создания большого корпуса эмоционального преобразования голоса, который будет нашим будущим акцентом.