Ранее мы предложили метод, который позволяет осуществлять непараллельное преобразование голоса (VC) с использованием варианта генеративных состязательных сетей (GANS) под названием StarGAN. Основные особенности нашего метода, получившего название StarGAN-VC, заключаются в следующем. Во-первых, он не требует параллельных высказываний, транскрипций или процедур выравнивания времени для тренировки генератора речи. Во-вторых, он может одновременно изучать сопоставления между несколькими доменами, используя единую генераторную сеть, чтобы в полной мере использовать доступные обучающие данные, собранные из нескольких доменов, для захвата скрытых функций, общих для всех доменов. В-третьих, он способен генерировать преобразованные речевые сигналы достаточно быстро, чтобы обеспечить реализацию в реальном времени, и требует всего нескольких минут обучающих примеров для создания достаточно реалистично звучащей речи. В этой статье мы опишем три формулировки StarGAN, включая недавно введенный новый вариант StarGAN под названием "Дополненный классификатор StarGAN (A-StarGAN)", и сравним их в непараллельной задаче преобразования голоса. Мы также сравниваем их с несколькими базовыми методами.
Выводы
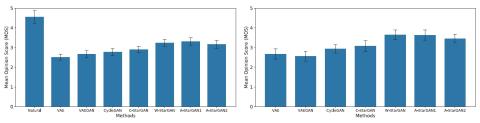
В этой статье мы предложили метод, позволяющий использовать непараллельное многодоменное преобразование голоса на основе StarGAN. Мы описали три формулировки StarGAN и сравнили их и несколько базовых методов в задаче преобразования идентичности непараллельных дикторов. С помощью объективных оценок мы подтвердили, что наш метод смог достаточно хорошо преобразовать личность диктора, используя всего несколько минут обучающих примеров. Заинтересованные читатели могут обратиться к [87], [88] для наших исследований других проектов сетевой архитектуры и улучшенных методов для CycleGAN-VC и StarGAN-VC.
Одним из ограничений предлагаемого метода является то, что он может преобразовывать входную речь только в голос диктора, видимый в данном обучающем наборе. Это связано с тем, что однократное кодирование (или простое встраивание), используемое для кондиционирования дикторов, не может быть обобщено на невидимых дикторов. Интересная тема для будущей работы включает в себя разработку системы преобразования голоса с нулевым проходом, которая может преобразовывать входную речь в голос невидимого диктора, просматривая только несколько его/ее высказываний. Как и в недавней работе [89], один из возможных способов достижения этой цели включает использование предварительного обучения встраиванию дикторов на основе метрической системы обучения для кондиционирования дикторов.