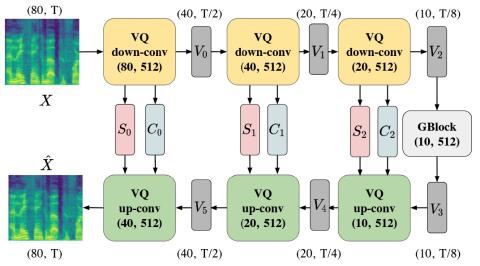
Преобразование голоса (VC) - это задача, которая преобразует тембр, акцент и тона исходного говорящего в аудио в другой звук, сохраняя при этом лингвистическое содержание. Это все еще сложная работа, особенно в условиях одного прохода. Методы преобразования голоса , основанные на автокодировщике, распутывают говорящего и содержание входной речи без указания личности говорящего, поэтому эти методы могут далее обобщаться на невидимых говорящих. Возможность распутывания достигается векторным квантованием (VQ), состязательным обучением или нормализацией экземпляра (IN). Однако несовершенное распутывание может повредить качеству выводимой речи. В этой работе для дальнейшего улучшения качества звука мы используем архитектуру U-Net в рамках системы преобразования голоса на основе автокодировщика. Мы находим, что для использования архитектуры U-Net необходим сильный информационный затор. Метод на основе VQ, который квантует скрытые векторы, может служить этой цели. Объективные и субъективные оценки показывают, что предложенный метод хорошо работает как в отношении естественности звука, так и в отношении сходства дикторов.
Выводы
В этой статье мы представляем новую модель для одноразового преобразования голоса. Мы используем U-Net в сочетании со слоями VQ для достижения высококачественного преобразования голоса. Благодаря хорошо продуманной архитектуре наша предлагаемая модель способна эффективно отделять информацию о дикторе и информацию о содержании элегантным способом только с потерей самовосстановления. Объективные результаты подтверждают сильную распутанность нашей модели, в то время как субъективные результаты могут подтвердить нашу гипотезу о том, что конструкция скипового соединения полезна для достижения высококачественного преобразования.