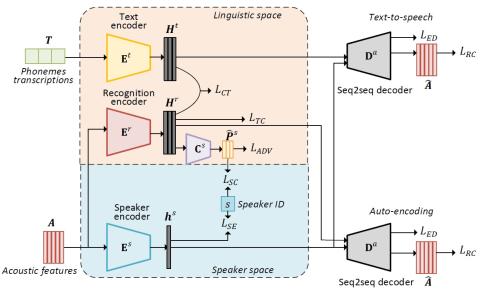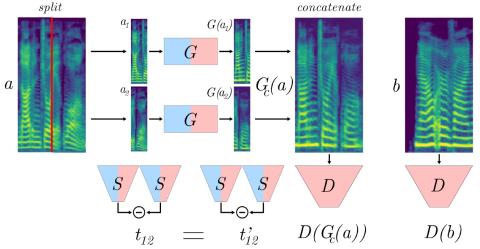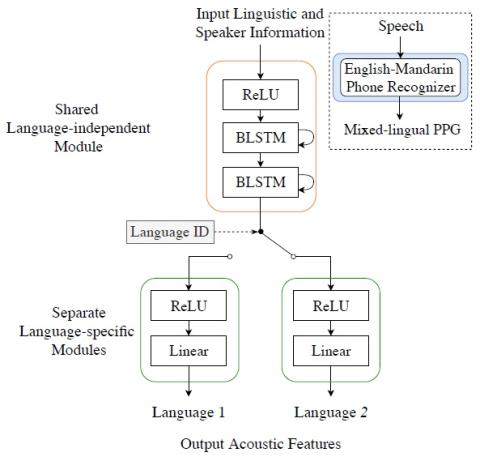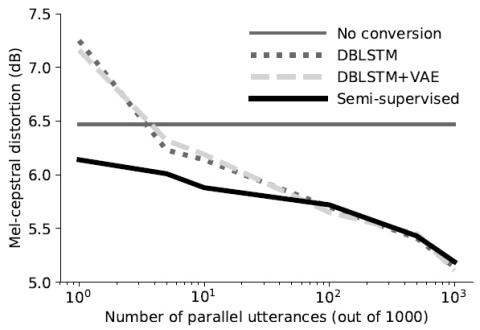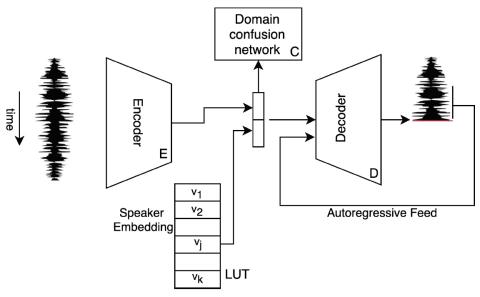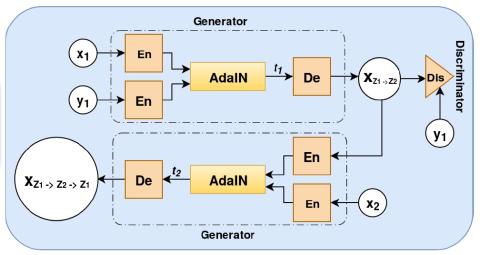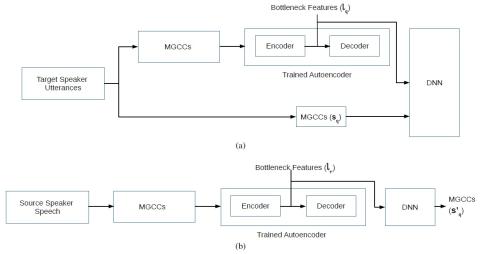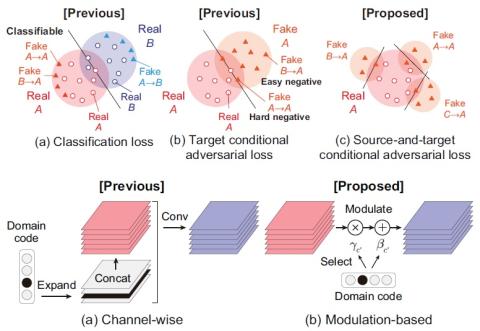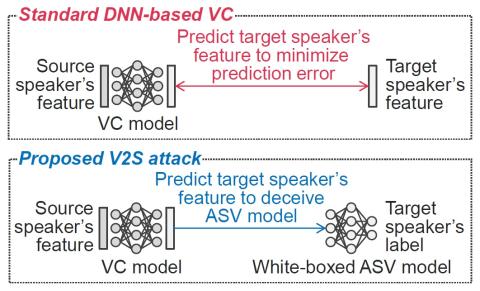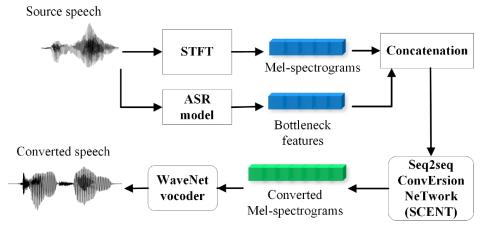
Последовательное акустическое моделирование для преобразования голоса
В этой статье представлена нейронная сеть под названием Sequence-to-sequence ConvErsion NeTwork (SCENT) для акустического моделирования в преобразовании голоса. На этапе обучения модель SCENT оценивается путем неявного сопоставления последовательностей признаков исходного и целевого говорящих, используя механизм внимания. На этапе преобразования акустические характеристики и длительность исходных звуков преобразуются одновременно с использованием единой акустической модели. В качестве акустических характеристик используются спектрограммы в масштабе Mel, которые содержат описания речевых сигнал...