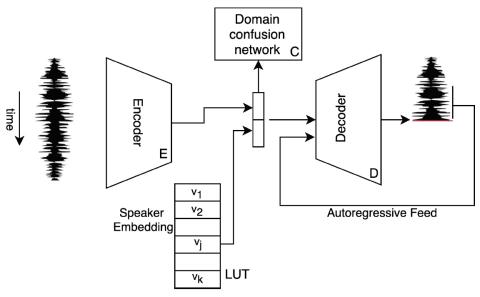
Мы представляем метод глубокого обучения для преобразования голоса певца. Предлагаемая сеть не зависит от текста или нот и напрямую преобразует аудио одного певца в голос другого. Обучение проводится без какого-либо контроля: никаких текстов или каких-либо фонетических особенностей, никаких нот и совпадающих сэмплов между певцами. Предлагаемая сеть использует единый кодер CNN для всех исполнителей, единый декодер WaveNet и классификатор, который обеспечивает независимое от певца скрытое представление. Каждый исполнитель представлен одним вектором встраивания, к которому привязан декодер. Чтобы работать с относительно небольшими наборами данных, мы предлагаем новую схему увеличения объема данных, а также новые потери при обучении и протоколы, основанные на обратной трансляции. Наша оценка свидетельствует о том, что в результате преобразования получаются естественные голоса, которые легко узнаваемы как у целевого исполнителя.
Выводы
Наш бесконтрольный метод позволяет получать высококачественный звук, который можно распознать как голос собеседника. Метод основан на использовании одного кодера CNN и одного условного декодера WaveNet. Сеть путаницы способствует тому, что новейшее пространство не зависит от певца, и применяются новые типы дополнений, чтобы преодолеть ограниченный объем доступных данных. Важно отметить, что обучение проводится в два этапа с использованием метода обратного перевода, который использует смешанные идентификаторы.
В ходе дальнейшей работы мы хотели бы выяснить, может ли подобный метод выполнять преобразование в присутствии фоновой музыки. Мы считаем, что это можно сделать без постороннего вмешательства, не полагаясь на контролируемый метод разделения голоса для предварительной обработки.