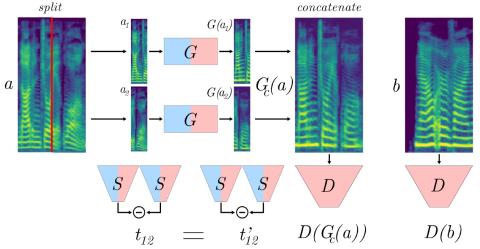
Традиционные методы преобразования голоса основаны на параллельной записи нескольких говорящих, произносящих одни и те же предложения. Однако для реальных приложений параллельные данные доступны редко. Мы предлагаем MelGAN-VC - метод преобразования голоса, который основан на непараллельных речевых данных и способен преобразовывать аудиосигналы произвольной длины из исходного голоса в целевой. Сначала мы вычисляем спектрограммы на основе данных формы сигнала, а затем выполняем преобразование предметной области с использованием архитектуры Generative Adversarial Network (GAN). Дополнительная сеть siamese помогает сохранять речевую информацию в процессе перевода, не жертвуя при этом возможностью гибко моделировать стиль говорящего на языке перевода. Мы тестируем наш фреймворк на базе данных чистых речевых записей, а также на примере зашумленной речи из реального мира. Наконец, мы применяем тот же метод для передачи музыкального стиля, переводя произвольно длинные музыкальные сэмплы из одного жанра в другой и демонстрируя, что наш фреймворк является гибким и может быть использован для приложений, работающих со звуком, отличных от преобразования голоса.
Выводы
Мы предложили метод для выполнения голосового перевода и других видов передачи звукового стиля, который не зависит от параллельных данных и способен переводить сэмплы произвольной длины. Архитектура генератора-дискриминатора и состязательное ограничение приводят к получению высокореалистичных выборок, в то время как потери при перемещении являются эффективным ограничением для сохранения контента при переводе, не зависящим от последовательности циклов. Мы провели эксперименты и продемонстрировали гибкость нашего метода при решении существенно различных задач. Мы считаем важным обсудить возможность неправильного использования нашей техники, особенно учитывая уровень реализма, достижимый как с помощью нашей техники, так и с помощью других методов. Хотя такие приложения, как преобразование музыкальных жанров, не представляют опасности, преобразование голоса может быть легко использовано не по назначению для создания поддельных аудиоданных по политическим или личным причинам. Важно также инвестировать ресурсы в разработку методов распознавания поддельных аудиоданных.