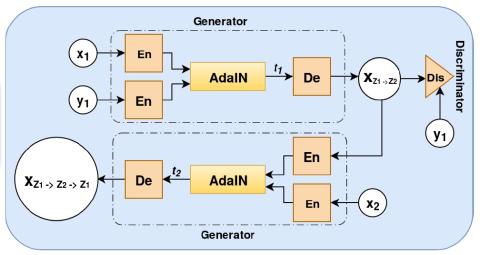
Преобразование голоса - это задача преобразования воспринимаемой идентичности говорящего от исходного к определенному целевому. Более ранние подходы, описанные в литературе, в основном заключаются в сопоставлении между заданными парами исходного и целевого говорящих. Разработка методов сопоставления для преобразования голоса "многие ко многим" с использованием непараллельных данных, включая обучение с нуля, остается менее изученной областью в преобразовании голоса. Большинство архитектур преобразования голоса "многие ко многим" требуют обучающих данных от всех целевых носителей, для которых мы хотим преобразовать голоса. В этой статье мы предлагаем новую архитектуру передачи стиля, которая также может быть расширена для генерации голосов даже для целевых носителей, чьи данные не использовались при обучении (т.е. в случае обучения с нулевым результатом). В частности, мы предлагаем адаптивную генеративную состязательную сеть (AdaGAN), новую архитектурную процедуру обучения, помогающую в изучении нормализованного, независимого от говорящего латентного представления, которое будет использоваться для генерации речи с различными стилями говорения в контексте преобразования голоса. Мы сравниваем наши результаты с новейшей архитектурой StarGAN-VC. В частности, AdaGAN демонстрирует относительное улучшение на 31,73% и 10,37% по сравнению со StarGAN в MOS-тестах на качество речи и сходство говорящих, соответственно. Ключевое преимущество предлагаемых архитектур заключается в том, что они дают эти результаты при меньшей вычислительной сложности. AdaGAN на 88,6% менее сложен, чем StarGAN-VC, с точки зрения скорости выполнения операций в секунду (FLOPS) и на 85,46% менее сложен с точки зрения обучаемых параметров.
Выводы и будущая работа
В этой статье мы предложили новый AdaGAN, в первую очередь, для непараллельной задачи преобразования голоса "многие ко многим". Более того, мы проанализировали предложенную нами архитектуру с использованием современного метода StarGAN-VC, основанного на GAN, для решения той же задачи. Мы знаем, что основная цель преобразования голоса - преобразовать голос говорящего-источника в голос говорящего-получателя, сохранив при этом лингвистический контент. Для достижения этой цели мы использовали алгоритм переноса стиля наряду с обучением состязательности. AdaGAN переводит стиль говорящего на языке-мишени в голос говорящего на языке-источнике без использования какого-либо функционального сопоставления лингвистического содержания речи говорящего на языке-источнике. Для решения этой задачи AdaGAN использует только один генератор и один дискриминатор, что приводит к снижению сложности. AdaGAN почти на 88,6% менее сложен в вычислительном отношении, чем StarGAN-VC.Мы провели субъективный анализ корпуса VCTK, чтобы показать эффективность предложенного метода. Мы можем ясно видеть, что AdaGAN дает более высокие результаты в субъективных оценках по сравнению со StarGAN-VC.
Вдохновленные работой Auto VC, мы также расширили концепцию Adagen для преобразования голоса с нулевым кадром в качестве независимого исследования и опубликовали результаты. Dagan - это первый основанный на GAN фреймворк для преобразования голоса с нулевым кадром. В будущем мы планируем изучить высококачественные вокодеры, а именно WaveNet, для дальнейшего улучшения качества передачи голоса. Наблюдаемая разница в восприятии между расчетной и реальной величиной указывает на необходимость изучения более совершенной целевой функции, которая может оптимизировать сетевые параметры архитектур на основе GAN, что также формирует нашу ближайшую будущую работу.